1. Foundations for Inference & Introduction to JASP¶
- Statistical inference is primarily concerned with understanding and quantifying the uncertainty of parameter estimates.
- Confidence Interval is a range of values where the true population value is likely to lie.
Foundations for Inference 1 3 4¶
- Point Estimate: A single value that best approximates the population parameter.
Uncertainty in point estimates¶
- Sampling Error:
- The natural variability that we expect between different random samples and the total population.
- It results from the randomness of the sampling process.
- It is quantified by the Standard Error as it is the most cared about measure of uncertainty.
- Bias:
- The point estimate is systematically higher or lower than the population parameter.
- It is a systemic tendency to under or over estimate the population parameter.
- It is especially important during the data collection phase.
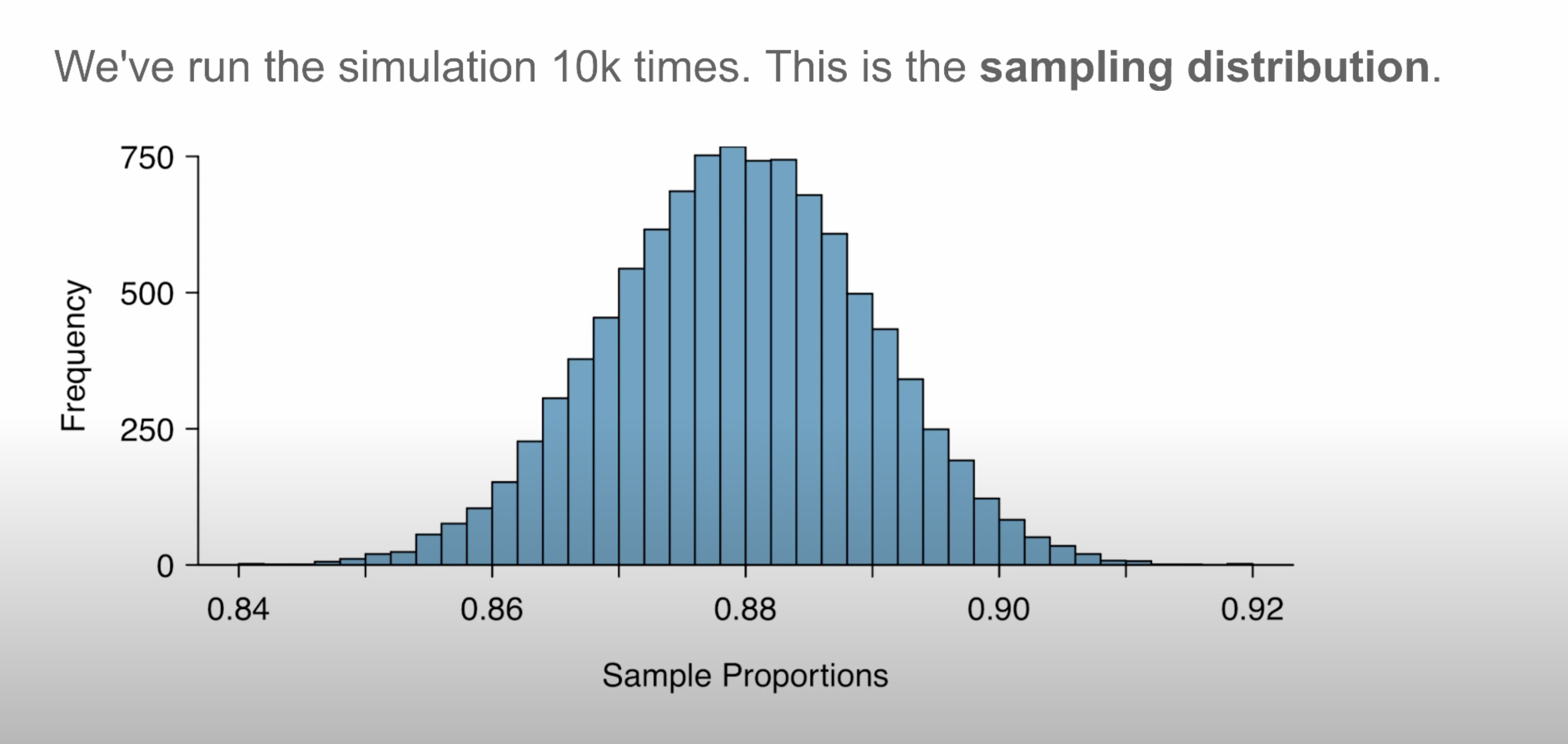
Sampling Distribution¶
- If we take many samples of the same size from the same population, the point estimates will vary from sample to sample.
- If we plot the distribution of point estimates, we get the sampling distribution.
- The distribution of point estimates based on samples of a fixed size from a certain population.
- It resembles a normal distribution (bell-shaped, symmetric) centered at the true population parameter.
- The mean of the sampling distribution is the population parameter.
- The standard deviation of the sampling distribution is the standard error.
Central Limit Theorem¶
- When observations are independent and the sample size is sufficiently large, the sampling distribution of the parameter estimate will follow a normal distribution with a mean equal to the population parameter \({\mu}_{\hat{p}}=p\) and a stand error computed as \(SE_{\hat{p}} = \sqrt{\frac{p(1-p)}{n}}\).
- For the CLT to hold, two conditions must be met
- The independence of observations.
- The success-failure condition:
- \(np > 10\).
- \(n(1-p) > 10\).
- The problem then becomes normal distribution problem:
- The mean of the sampling distribution is the point estimate.
- The standard error is the standard deviation of the sampling distribution.
- We plot the distribution by finding the z-score and using the normal distribution table.
- \(z_{1} = \frac{\hat{p_{min}} - p}{SE_{\hat{p}}}\), \(z_{2} = \frac{\hat{p_{max}} - p}{SE_{\hat{p}}}\).
- It is hard to find z1 nad z2 as it requires us to make more samplings.
- We use the confidence interval to estimate the range of values where the true population parameter is likely to lie.
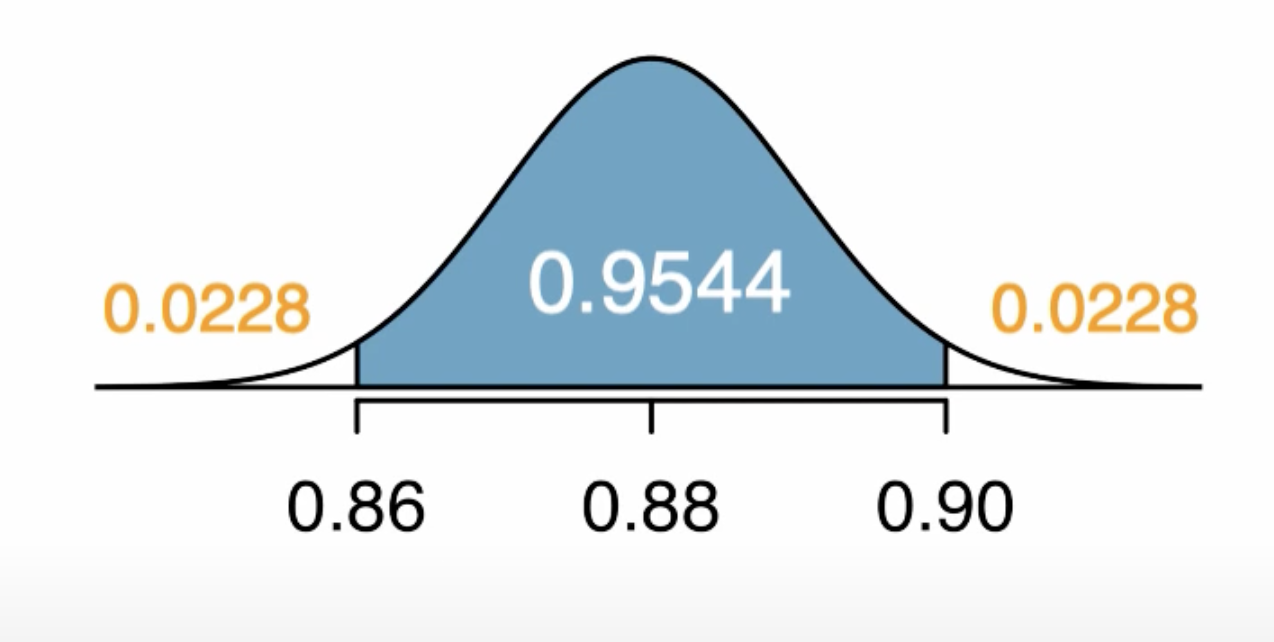
- With a 95% confidence level, we can say that \(z_{1} = -1.96\) and \(z_{2} = 1.96\).
- With a 99% confidence level, we can say that \(z_{1} = -2.58\) and \(z_{2} = 2.58\).
The Plug-in Principle¶
- If we have a point estimate for a sample, and we confirmed that the central limit theorem holds and the sampling distribution is approximately normal, we can use the plug-in principle to plugin the sample point estimation (sample parameter) in place of the population parameter.
Confidence Intervals¶
- The problem is the point estimate (of a sample) may not truly represent the population parameter.
- Instead of providing a single point estimate, we provide a range of values where the true population parameter is likely to be.
- Constructing 95% confidence interval:
- In a normal distribution, 95% of the observations fall within 1.96 standard deviations of the mean (distribution center).
- Thus, if a point estimate can be modeled using a normal distribution, we can construct a plausible range with 95% confidence as \([\hat{p} - 1.96\times{SE}, \hat{p} + 1.96\times{SE}]\)
- Interpreting confidence level:
- We are 95% confident that the true population parameter lies within the interval.
- For example, [0.45, 0.55] is the 95% confidence level for people supporting solar panels, and we can say:
- We are 95% confident that the actual percentage of public supporting solar panels is between 45% and 55%.
- Common confidence levels:
- 90% confidence level: \(z = 1.645\) and the interval is \(\hat{p} \pm 1.645\times{SE}\).
- 95% confidence level: \(z = 1.96\) and the interval is \(\hat{p} \pm 1.96\times{SE}\).
- 99% confidence level: \(z = 2.58\) and the interval is \(\hat{p} \pm 2.58\times{SE}\).
- Confidence intervals says nothing about individual observations.
- Confidence intervals says nothing about future samples.
- It is NOT the probability that the true parameter lies within the interval.
Introduction to JASP 2 5¶
- Data can be downloaded from https://osf.io/bx6uv/
Descriptive Statistics¶
- Descriptive statistics and related plots are a succinct way of describing and summarising data but do not test any hypotheses. it includes:
- Measures of central tendency.
- Measures of dispersion.
- Percentile values.
- Measures of distribution.
- Descriptive plots.
Central Tendency¶
- The tendency for variable values to cluster around a central value.
- Mean, Median, Mode.
- Mean: M or \(\bar{x}\). It equals the sum of all values divided by the number of values. It equals the average. It is sensitive to outliers.
- Median: Mdn. It is the middle value when all values are ordered. It is less sensitive to outliers.
- Mode: The most frequent value.
Dispersion¶
- The spread of values around the central value.
- Standard Error of the mean, standard deviation, coefficient of variation, median absolute deviation, median absolute deviation Robust, inter-quartile range, variance, confident interval.
- Standard Error of the mean (SE):
- It is the standard deviation of the sampling distribution of the mean.
- It measures how far the sample mean from the true population mean.
- It decreases as the sample size increases.
- Standard Deviation (SD):
- It quantifies the amount of dispersion of the data around the mean.
- Low SD means that values are close to the mean.
- High SD means that values are far from the mean or dispersed on a wider range.
- It is sensitive to outliers.
- It is the square root of the variance.
- It is the average distance of each data point from the mean.
- It is the square root of the average of the squared differences between each data point and the mean.
- Coefficient of Variation (CV):
- It measures the relative dispersion of the data.
- It differs from the standard deviation which measures the absolute dispersion.
- Median Absolute Deviation (MAD):
- It is the median of the absolute differences between each data point and the median.
- It is less sensitive to outliers.
- It only works with normally distributed data, otherwise, it is not recommended and SD is more useful.
- Median Absolute Deviation Robust (MAD Robust):
- It is the median absolute deviation for the data but adjusted by a factor for asymptotically normal consistency.
- Inter-Quartile Range (IQR):
- It is the difference between the 75th percentile and the 25th percentile.
- It is similar to MAD but less robust.
- Variance:
- It is the average of the squared differences between each data point and the mean.
- It is the square of the standard deviation.
- It is sensitive to outliers.
- Confidence Intervals:
- It is a range of values where the true population value is likely to lie.
Quartiles¶
- Quartiles are where datasets are split into 4 equal quarters, normally based on rank ordering of median values.
- The 1st quartile = 25th percentile = lower quartile.
- The 2nd quartile = 50th percentile = median.
- The 3rd quartile = 75th percentile = upper quartile.
- The 4th quartile = 100th percentile = maximum value.
- The inter-quartile range = 3rd quartile - 1st quartile.
- The data is ordered like we do when computing the median, and then we pick the values at the 25th, 50th, and 75th percentiles.
Distribution¶
- The distribution of data can be described by the shape, skewness, and kurtosis.
- In normal distribution, the skewness and kurtosis should be close to 0.
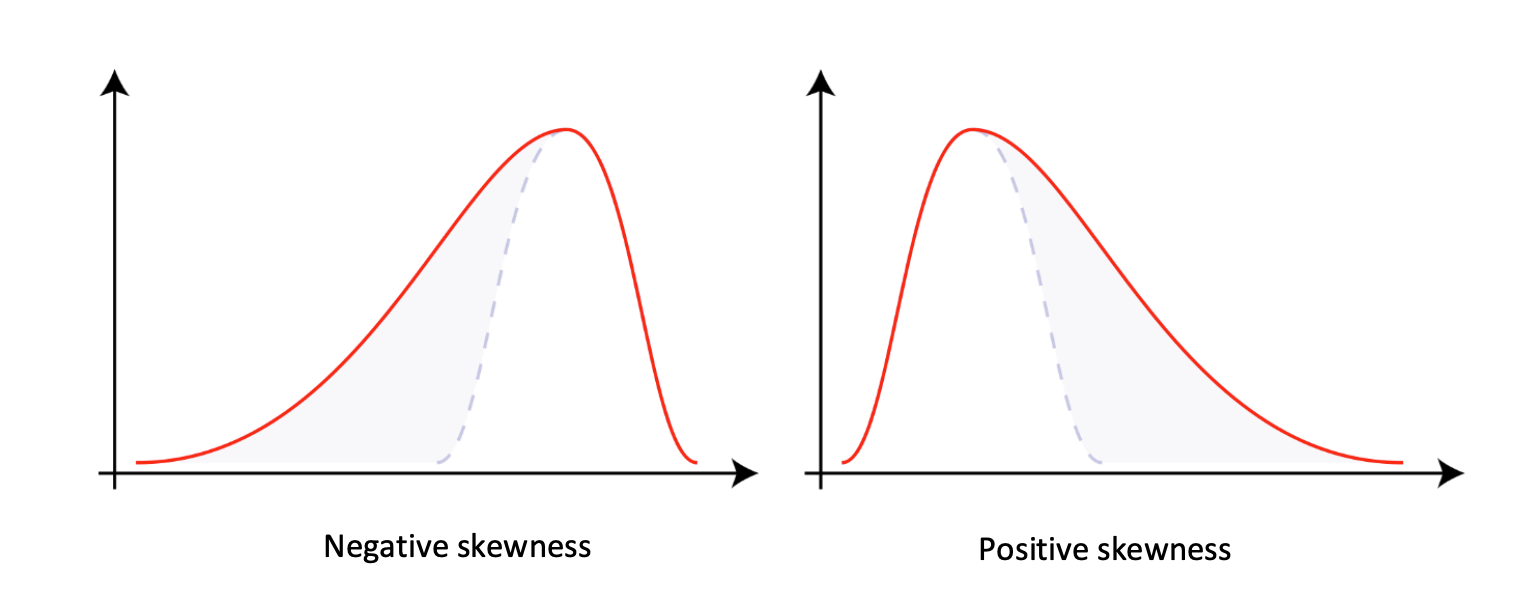
- Skewness:
- It describes the shift of the distribution away from normal distribution.
- Skewed distribution loses symmetry and the bell is shifted to the left or right.
- Negative skewness show the mode moves to the right which causes left tail.
- Positive skewness show the mode moves to the left which causes right tail.
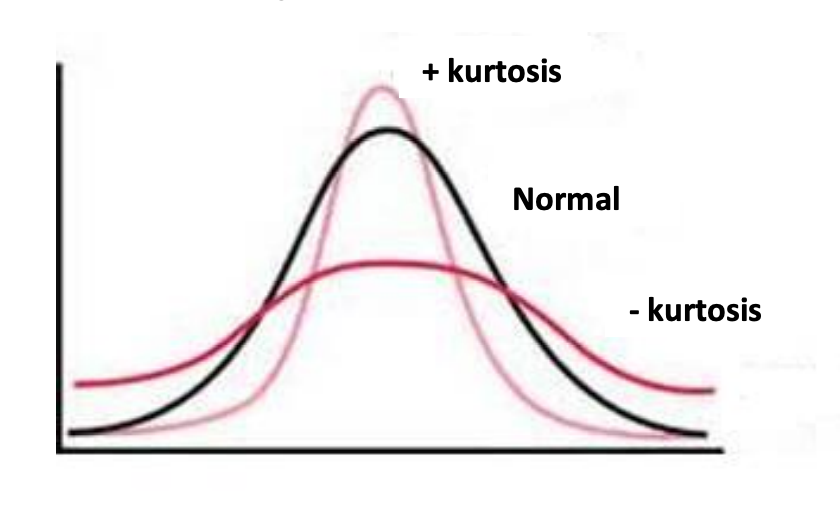
- Kurtosis:
- It describes how pointy or flat the bell is.
- Positive kurtosis means the distribution is more peaked than a normal distribution., and tails are smaller.
- Negative kurtosis means the distribution is less peaked than a normal distribution, and tails are larger.
- Shapiro-Wilk Test:
- It is a test for normality, it assesses weather the data is significantly different from a normal distribution.
References¶
-
Diez, D. M., Barr, C. D., & Çetinkaya-Rundel, M. (2019). Openintro statistics - Fourth edition. Open Textbook Library. https://www.biostat.jhsph.edu/~iruczins/teaching/books/2019.openintro.statistics.pdf Read Chapter 5 - Foundations for Inference from page 168-205. Section 5.1 - Point estimates and sampling variability. Section 5.2 - Confidence intervals for a proportion. Solve the following practice exercises as homework from the attached: Practice Exercises – Unit 1 https://my.uopeople.edu/pluginfile.php/1897551/mod_book/chapter/531355/Practice%20Excercises%20-%20%20Unit%201_Final.pdf ↩
-
Goss-Sampson, M. A. (2022). Statistical analysis in JASP: A guide for students (5th ed., JASP v0.16.1 2022). https://jasp-stats.org/wp-content/uploads/2022/04/Statistical-Analysis-in-JASP-A-Students-Guide-v16.pdf Read Page 2-31 ↩
-
OpenIntroOrg. (2019a, September 02). Foundations for inference: Point estimates [Video]. YouTube. https://youtu.be/oLW_uzkPZGA ↩
-
OpenIntroOrg. (2019b, September 6). Intro to confidence intervals via proportions [Video]. YouTube. https://youtu.be/A6_W8qY8zJo ↩
-
JASP Statistics. (2022, October 05). Introduction to JASP [Video]. YouTube. https://youtu.be/APRaBFC2lEQ ↩