WA2. Dictionaries and Index Construction¶
I was confused with instructions of the assignment, so I divided my submission into the 3 parts:
- Statement: Includes the statement of the assignment, formatted in an easy-to-follow format.
- Summary: description of the assignment, my observations, and final notes.
- Changes: A step by step documentation of all my interactions and changes to the code.
Statement¶
- The following example presents an example of what our text calls single pass in memory indexing.
- This indexer has been developed using the Python scripting language.
- Your assignment will be to use this code to gain an understanding of how to generate an inverted index.
- This simple python code will read through a directory of documents, tokenize each document and add terms extracted from the files to an index.
- The program will generate metrics from the corpus and will generate two files: a document dictionary file and a terms dictionary file.
- The terms dictionary file will contain each unique term discovered in the corpus in sorted order and will have a unique index number assigned to each term.
- The document dictionary will contain each document discovered in the corpus and will have a unique index number assigned to each document.
- From our reading assignments, we should recognize that a third document is required that will link the terms to the documents they were discovered in using the index numbers. Generating this third file will be a future assignment.
- We will be using a small corpus of files that contain article and author information from articles submitted to the Journal “Communications of the ACM”. The corpus is in a zip file in the resources section of this unit as is the example python code.
- You will need to modify the code to change the directory where the files are found to match your environment. Download the python file or copy its contents to your blank “Untitled” Python file and save it with name “Code_indexer.py”.
- Although this will not build a complete index it will demonstrate key concepts such as
- Traversing a directory of documents.
- Reading the document and extracting and tokenizing all of the text.
- Computing counts of documents and terms.
- Building a dictionary of unique terms that exist within the corpus.
- Writing out to a disk file, a sorted term dictionary.
- As we will see in coming units the ability to count terms, documents, and compiling other metrics is vital to information retrieval and this first assignment demonstrates some of those processes.
- Requirements:
- Your terms dictionary and documents dictionary files must be stored on disk and uploaded as part of your completed assignment.
- Your indexer must tokenize the contents of each document and extract terms.
- Your indexer must report statistics on its processing and must print these statistics as the final output of the program.
- Number of documents processed.
- Total number of terms parsed from all documents.
- Total number of unique terms found and added to the index.
Summary¶
The points 6,7, and 13 from the summary above summarize all the requirements of this assignment. The rest of the points are instructions and explanations. The main purpose of the assignment is to practice building a single pass memory indexer, where we build an inverted index in memory first, then we write that index to disk for future use.
A single pass indexer means that indexer will only read the corpus once, from start to finish, and it updates a an in-memory dictionary(ies) of documents, terms, and postings. Then it writes the contents of these dictionaries to disk when the indexer has finished.
Later queries to such an indexer, may be answered by reading the index from disk, and searching for terms supplied by the query; but it is common for large indexes to be partially stored in memory, where the most frequent terms are stored in memory, and the rest are stored on disk. However, for such a small index that we are building, it is possible to store the whole index in memory.
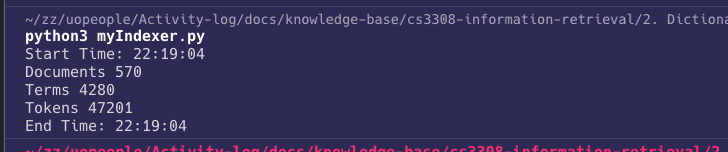
Here are the results of running the indexer against the supplied corpus:
- There are 570 documents (files) in the corpus.
- There are 47201 Tokens in the corpus (all words in all documents).
- There are 4280 Terms in the corpus (unique words in all documents).
- Indexing time is less than 1 second.
Here are my observations and notes:
- Using the same folder to store the results:
- If you use the same folder as the corpus folder to store the results, that is, the two files
documents.datandindex.dat. - Then the indexer index these files as well, and the stats will be wrong.
- It is a problem if you run the indexer and saved the files, and then re-run again while testing.
- The number of files will be 572, and the number of tokens will be 72279; and the number of terms will be 18002.
- The term and its id stored in a
,separated line, this will be counted as a unique term, unless the regular expressions are updated. - Also the document paths may contain spaces, which may generate more of fake terms.
- If you use the same folder as the corpus folder to store the results, that is, the two files
- Documents paths:
- The code stores the entire path of the document, including all folders and sub-folders, up to the file name.
- This can be a waste of space, as the path is repeated for each document.
- For our index, all files are stored in one location, that is,
Documents/cacm/, for example. - Storing only file names, while maintaining the root folder in a higher-up congfiguration file, will save space.
- HTML tags:
- The regular expressions at the start of the file does not ignore html tags, and extract them as text after removing the
<and>characters. - This may be a problem as searching for the word
htmlwill return all documents since all html files include the<html>tag. - This may greatly increase the index size and the time it takes to build the index, and response time.
- This may reduce the accuracy of the search results.
- This may decrease both precision and recall.
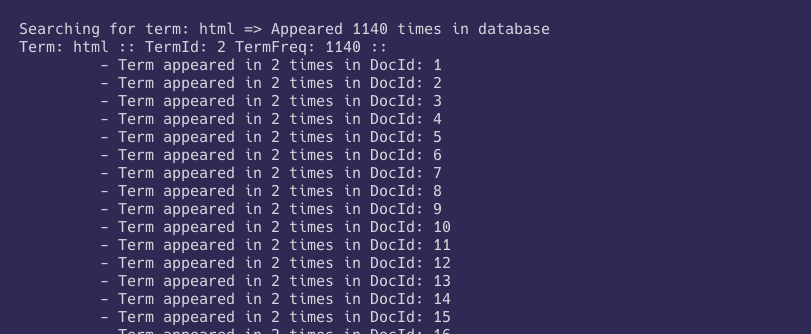
- To test this, I searched for the word
htmland it returned 1140 documents, that is exactly the number of html files in the corpus * 2; one for<html>and one for</html>.
- The regular expressions at the start of the file does not ignore html tags, and extract them as text after removing the
Changes¶
- Found the database named
indexer_part2.dbin some part of the code, andindexer.dbin other parts. Changed all toindexer.db. - I called
select_all_records_by_author(get_cursor())inmain()to test the function. It works fine and returned all documents stored in the database, which ere 570 documents. - I created
analyze_dbfunction, and deletedselect_all_records_by_authorfunction.
def analyze_db():
cur = get_cursor()
docs = cur.execute("SELECT * FROM DocumentDictionary").fetchall()
print("\n\n Found %i documents in the DocumentDictionary table\n" % len(docs))
print("\nHere is a listing of the rows in the table DocumentDictionary\n")
for row in docs:
print(row)
terms = cur.execute("SELECT * FROM TermDictionary").fetchall()
print("\n\n Found %i terms in the TermDictionary table\n" % len(terms))
print("\nHere is a listing of the rows in the table TermDictionary\n")
for row in terms:
print(row)
postings = cur.execute("SELECT * FROM Posting").fetchall()
print("\n\n Found %i postings in the Posting table\n" % len(postings))
print("\nHere is a listing of the rows in the table Posting\n")
for row in postings:
print(row)
-
As per the instructions in the course forum, I removed references to database and used
documentsDictionary, which is an in-memory dictionary, that holds document id as key, and path to the document as value. -
To view what’s happening, I added the following code to
main(), that prints the contents ofdocumentsDictionaryanddatabasein a readable format:
# nicely print the database
for k in database.keys():
print(
"%s :: TermId: %i TermFreq: %i" %
(k, database[k].termid, database[k].termfreq),
end=' :: '
)
for docid in database[k].docids.keys():
print("\n \t - DocId: %i Appearances: %i" %
(docid, database[k].docids[docid]), end=' ')
print("")
# print(documentsDictionary)
for docId in documentsDictionary.keys():
print("DocId: %i :: %s" % (
documentsDictionary[docId].docId, documentsDictionary[docId].docName), end='')
print("")
- The next task is to write the
documentsDictionaryto a file nameddocuments.dat. Where each line is in format:documentPath, documentId. I created a function namedwrite_documents_dot_dat()to do that:
def write_documents_dot_dat():
global
documentsFile = open(folder+'/'+'documents.dat', 'w')
for docId in documentsDictionary.keys():
documentsFile.write(
documentsDictionary[docId].docName+','+str(documentsDictionary[docId].docId)+os.linesep)
documentsFile.close()
- The next task was to write all extracted terms to a file named
index.dat. Where each line is in format:term, termId. I created a function namedwrite_index_dot_dat()to do that:
def write_index_dot_dat():
indexFile = open(folder+'/'+'index.dat', 'w')
for k in database.keys():
indexFile.write(k+','+str(database[k].termid)+os.linesep)
indexFile.close()
- I noticed the terms in the index are not sorted, so I updated
write_index_dot_dat()to sort the terms before writing them to the file:
def write_index_dot_dat():
indexFile = open(folder+'/'+'index.dat', 'w')
for k in sorted(database.keys()):
indexFile.write(k+','+str(database[k].termid)+os.linesep)
indexFile.close()
- I cleaned up may main function, removed unnecessary code and comments, and it looks like this now:
if __name__ == '__main__':
t = time.localtime()
print("Start Time: %.2d:%.2d:%.2d" % (t.tm_hour, t.tm_min, t.tm_sec))
corpusFolder = "/Users/ahmad/zz/uopeople/Activity-log/docs/knowledge-base/cs3308-information-retrieval/0. project/corpus/cacm" # PATH TO BE EDITED
walkdir(corpusFolder)
print("Documents %i" % documents)
print("Terms %i" % terms)
print("Tokens %i" % tokens)
# nicelyPrint()
write_documents_dot_dat()
write_index_dot_dat()
t2 = time.localtime()
print("End Time: %.2d:%.2d:%.2d" % (t2.tm_hour, t2.tm_min, t2.tm_sec))
- To test the code, I created a function
search_term(term)where atermis passed as an argument, and its information is retrieved from database; then I would manually verify the term frequency and the Postings List.
def search_term(term):
if term in database.keys():
print("Searching for term: %s => Appeared %i times in database" %
(term, database[term].termfreq), end='\n')
print("Term: %s :: TermId: %i TermFreq: %i" % (term, database[term].termid,
database[term].termfreq), end=' :: ')
for docid in database[term].docids.keys():
print("\n \t - Term appeared in %i times in DocId: %i" %
(database[term].docids[docid], docid), end=' ')
print("")
else:
print("Term: %s :: Not Found" % term)
And here is the results of searching for the term html:
References¶
- UoPeople (2023). CS 3308 - Information Retrieval. Unit 2: Dictionaries and Index Construction. Introduction. https://my.uopeople.edu/mod/book/view.php?id=392839&chapterid=471100