4. Multiprocessor Scheduling and Abstraction¶
Introduction¶
- This unit will introduce you to concepts:
- Multiprocessor scheduling: schedule multiple processes to share resources.
- Physical memory virtualization.
Scheduling: Proportional Share 1¶
Lottery scheduling¶
- also known as fair-share scheduling or lottery scheduling.
- concept: give each job a certain percentage of CPU time.
- ticket: a number that represents a job’s share of CPU time.
- Periodically, the scheduler picks a random ticket number and runs the job that owns that ticket.
- Example, process A has 75 tickets (0 -> 74), process B has 25 tickets (75 -> 99). Lottery scheduling example:

- The use of randomness in lottery scheduling leads to a probabilistic correctness in meeting the desired proportion, but no guarantee.
- Advantages of using randomness:
- avoid strange edge cases. e.g. Worst case scenarios for other algorithms.
- Random is lightweight process: less stuff to keep track of (less overhead).
- Random is fast: generating a random number, then deciding next process happens in constant time.
- Lottery scheduling mechanisms:
- tickets currency:
- some tickets weights more than others.
- e.g. 1 ticket of currencyA worth 10 units of CPU time (currency multiplier = 10), 1 ticket of currencyB worth 1 unit of CPU time (currency multiplier = 1).
- ticket transfer:
- process can transfer tickets to other processes.
- e.g. process A can transfer 10 tickets to process B.
- useful when a process A asks B to do some work for it, process A can transfer tickets to B to get the result faster.
- ticket inflation:
- process can inflate tickets, aka. change the number of tickets it owns.
- e.g. process A can inflate 10 tickets to 100 tickets.
- tickets currency:
Stride scheduling¶
- Stride scheduling:
- a deterministic fair-share scheduler.
- Each job in the system has a stride, which is inverse in proportion to the number of tickets it has (stride A = N / number of tickets of A) where N is a large number.
- Each job has a counter (pass), initialized as 0, incremented by its stride each time it runs.
- Schedular uses both pass and stride to decide which job to run next.
- Always choose the job with the smallest pass, and increment its pass by its stride. If there are multiple jobs with the same pass, choose randomly.
- Lottery scheduling achieves the proportions probabilistically over time; stride scheduling gets them exactly right at the end of each scheduling cycle.
- drawbacks:
- It is hard to decide if a new job comes in the middle of a scheduling cycle, its pass would be 0, and it would be scheduled immediately.
Linux Completely Fair Scheduler (CFS)¶
- CFS:
- Implements fair-share scheduling, but in efficient manner.
- Uses virtual runtime (vruntime) to track the amount of CPU time each process has used.
- CFS will always choose the process with the smallest vruntime to run next.
- CFS parameters:
- sched_latency:
- determine how long a process should run before switching to another process, aka. dynamic time slice.
- typically 48ms, then divide by the number of CPUs (n).
- min_granularity:
- the minimum time slice a process can run, the minium value for sched_latency.
- typically 6ms, there will be no sched_latency less than this value, no matter how many processes there are.
- weighting (Niceness):
- nice values between -20 and 19, where -20 is the highest priority and 19 is the lowest.
- default value is 0, which is the default priority.
- time_slice of process K = ( weight [nice of process K] / sum of all weights in the system ) * sched_latency.
- vruntime of process K = vruntime of process K + ( weight of nice 0 / weight of process k) * runtime of process K.
- sched_latency:
- Red-Black Trees:
- CFS uses red-black trees to keep track of the processes in the system.
- properties of red-black tress:
- balanced: the height of the tree is O(log n).
- keeps runnable processes only, which makes faster to find the next process to run.
- most operations (insert, delete, find) are O(log n).
- processes are sorted by vruntime.
- When a process wakes up from sleep, its vruntime is updated to the minimum vruntime found in the tree, and it is inserted into the red-black tree.
Multiprocessor Scheduling 2¶
- multi-core processors:
- multiple CPU cores on a single chip.
- useful, since architects can not make a single CPU core faster without increasing power consumption.
- one program can only run on one core at a time, so programs did not go faster. unless you design your program to run in
parallel(using threads). - multi threaded apps can spread work across multiple cores, and thus run faster.
- scheduling becomes more complex on multi-core processors.
Multiprocessor Architecture¶
- main memory: a large, slower memory that stores all the data in the system.
- most fundamental difference between single-core and multi-core processors:
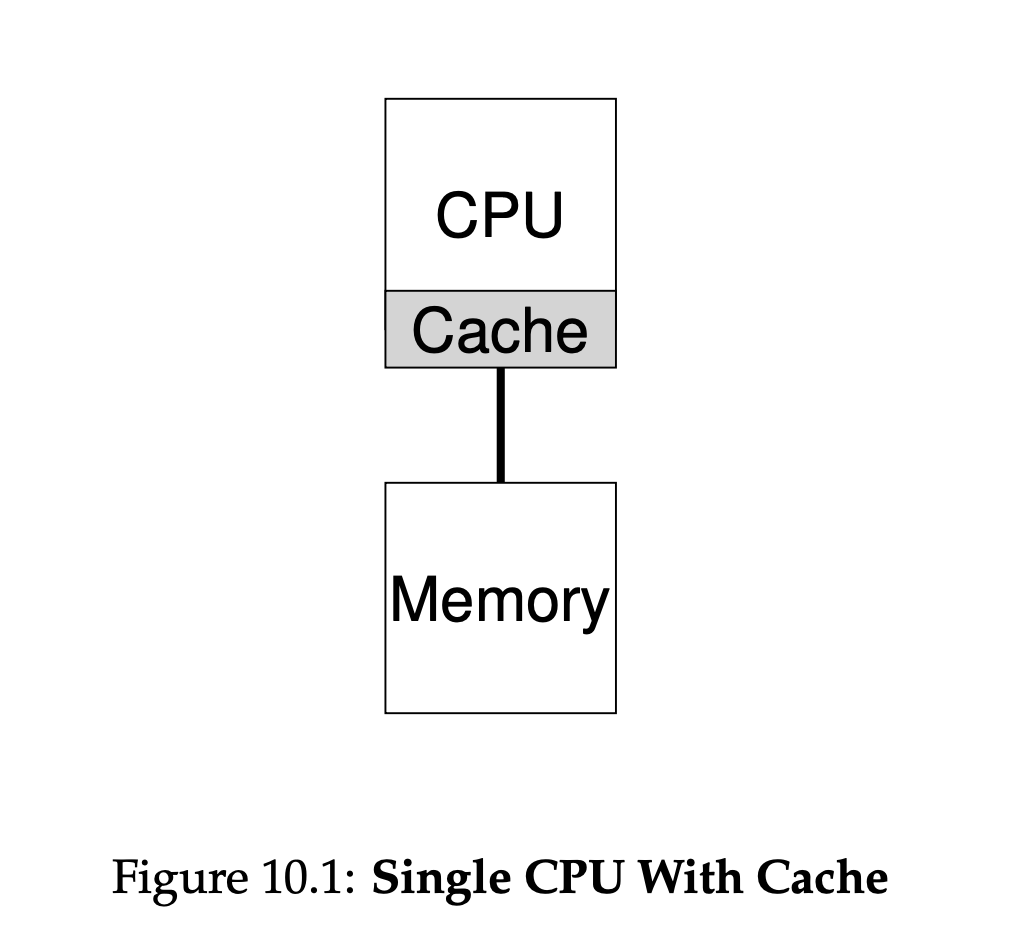
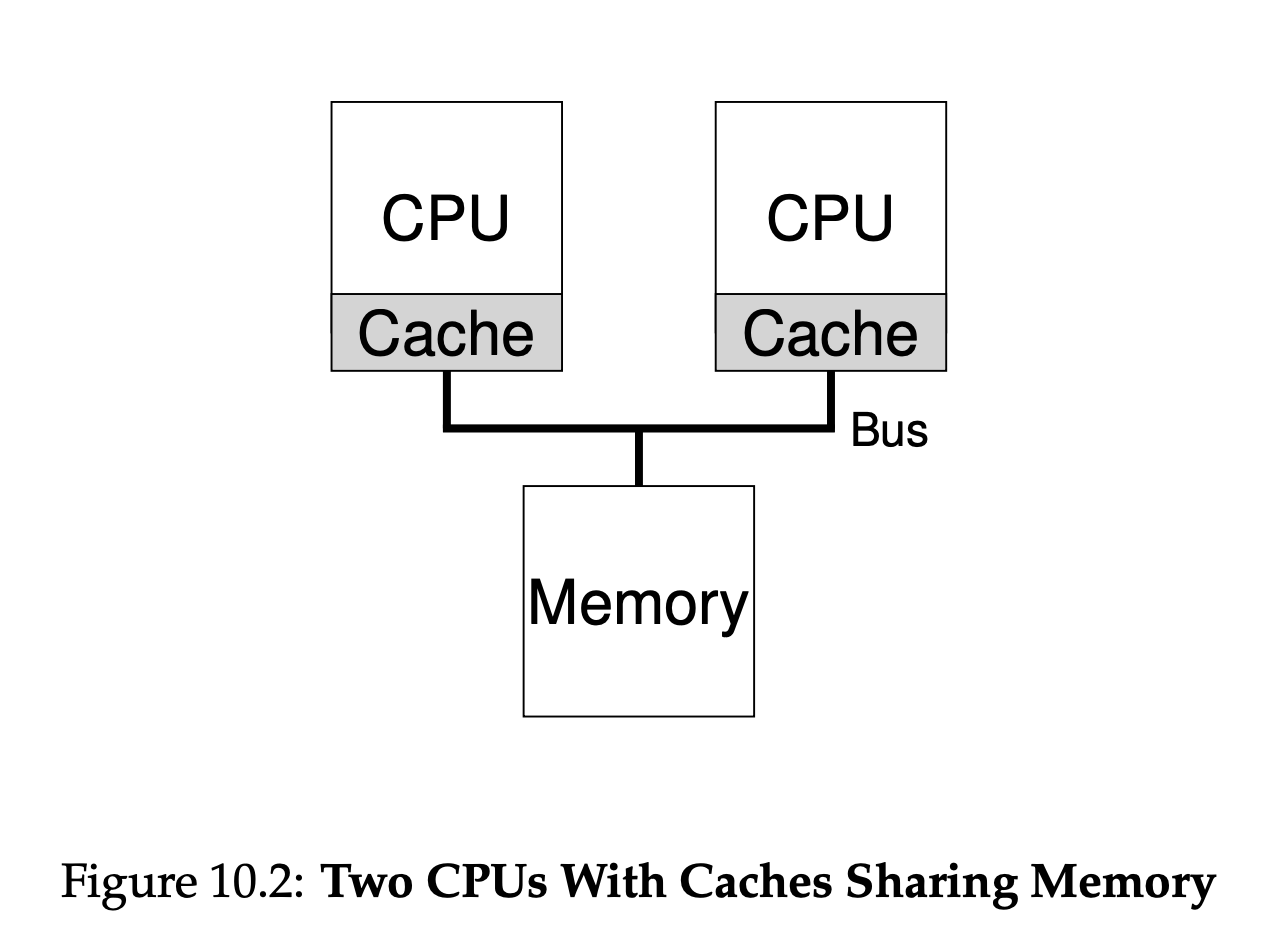
- single core processors have the main memory connects to the single CPU with one cache close to the CPU.
- multi-core processors have the main memory connects to multiple CPUs through a bus; each of these CPUs has its own cache.
Cache memory¶
- cache: a small, very fast memory that is used to store recently used (aka, popular) data; which is the data that is most likely to be used again soon.
- 2 types of caching:
- temporal locality: data that is used recently is likely to be used again soon.
- spatial locality: if a program uses data in location x, it is likely to use data in location x+1 soon.
- systems can go faster by keeping the frequently accessed data in cache, and only accessing main memory when necessary.
- cache incoherence: is a problem that happen when a program executes on one CPU, and updates the CPU’s cache, but not main memory; the next run, the program goes to a different CPU, the new CPU will fetch data from the main memory which has not been updated yet.
- bus snooping:
- is a solution for the cache incoherence problem.
- All caches of all CPUs listen to updates on the main memory through the bus; invalidate their own cache if they see an update to a location that is in their cache.
- This is very complex approach, since all CPUs need to listen to all updates on the bus, and sometimes that is difficult.
- cache affinity:
- When a process first runs on a specific CPU, it will build its cache in that CPU.
- When the process to resume (rescheduled), it is beneficial to run it on the same CPU, since it will have its cache built already.
- OS must consider cache affinity when scheduling processes on multi-core processors.
Synchronization¶
- When working with multiple CPUs, we need to make sure that the CPUs do not interfere with each other.
- when accessing (or updating) a shared resource, we need to make sure that only one CPU can access it at a time.
- we guarantee this by using mutual exclusion primitives (aka. locks, or mutex) to ensue correctness when implementing concurrency.
- mutex or locks can degrade performance significantly, since they are used to ensure correctness, not performance.
Single-Queue MultiProcessor Scheduling (SQMS)¶
- SQMS:
- puts all runnable processes in a single queue.
- advantages: simple, easy to implement.
- drawbacks: lack of scalability: to ensure correctness, locks are implemented. locks can not scale. With more CPUs, locks overhead becomes more significant.
- solutions: to reduce the overhead of locks, the scheduler can apply cache affinity, which means a job may run on the same CPU on future.
- solutions: load balancing: applying the cache affinity will stick most of the jobs to some CPUs, but it is fine for some jobs to migrate (bounce) on other CPUs to balance the load.
Multi-Queue MultiProcessor Scheduling (MQMS)¶
- creates a separate queue for each CPU.
- each queue has its own scheduling algorithm.
- when a new job arrives it gets added to one of the queues depending on some policy (usually, random, or to the queue with the least number of jobs).
- Once a job is assigned to a queue, it stays on that queue till it is done which:
- removes the cache incoherence problem, thus no need for locks.
- no need for synchronization.
- cache affinity is on the maximum, since the job will run on the same CPU for the entire time.
- Advantages over SQMS:
- no need for locks, synchronization, and cache incoherence => scalable with big number of CPUs and jobs.
- more performance, since cache affinity is on the maximum.
- disadvantages:
- load Imbalance:
- since jobs are assigned to queues randomly, some queues may have more jobs or finish faster than others.
- this leaves some CPUs idle, while others are busy.
- to solve this, we can use load balancing by doing migration:
- constantly move jobs from busy queues to idle queues.
- another solution is work stealing:
- idle queues constantly poll busy queues to steal jobs from them.
- work stealing has also some overhead, but the key is to find the exact balance between doing it more or less often.
- load Imbalance:
Linux Multiprocessor Schedulers¶
- Three linux schedulers emerged:
- The O(1) scheduler:
- multi-queued
- priority based (similar to MLFQ), schedules the highest priority job.
- The Completely Fair Scheduler (CFS):
- multi-queued.
- deterministic proportional-share scheduler.
- The BF (Budget Fair) scheduler (BFS):
- single-queued.
- proportional-share scheduler based on Earliest Eligible Virtual Deadline First (EEVDF).
- The O(1) scheduler:
Memory Address Spaces 3¶
- Early systems:
- memory was not complex, it has 2 things: OS and the user program.
- OS will occupy the first part of the memory, and the user program will occupy the rest.
- OS processes + one single user process.
- multiprogramming: the ability to run multiple processes at the same time, by switching between them to maximize CPU utilization and efficiency.
- time sharing:
- to maintain process interactivity, run a process for a short time giving all CPU and memory, then switch to another process.
- in between switches, OS will save process data to disk.
- Later, saving to disk is replaced by saving to main memory, which is much faster to access.
- notions of isolation, protection, and security became important, so the address space concept was introduced.
The Address Space¶
- address space:
- easy to use abstraction for the memory.
- represents the memory of a process.
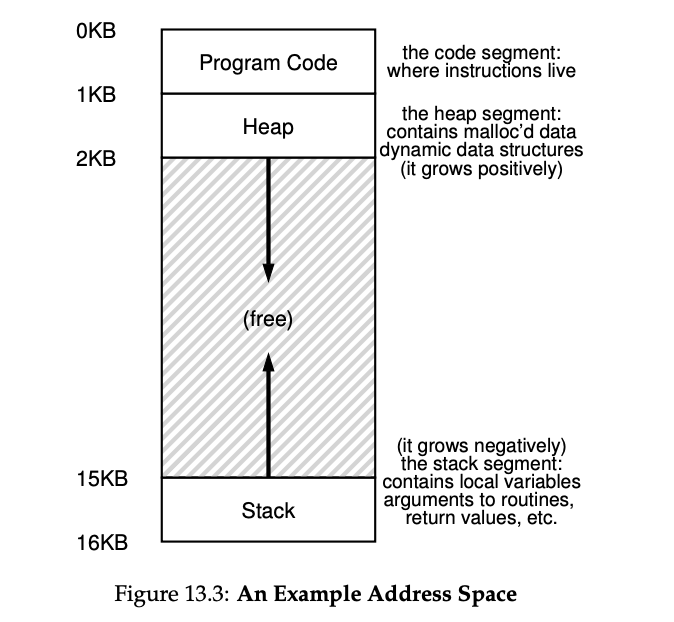
- Goals of the address space:
- transparency: the process should not be aware of the address space.
- efficiency: the address space should be efficient to use.
- protection: the address space should protect the process from other processes.
Multiple Processors Scheduling in Operating System 4¶
- Multiple Processors Scheduling:
- The device has more than one Physical CPU; these CPUs share the load of the processes so that multiple processes can run simultaneously.
- It is more complex than Single Processor Scheduling.
- The multiple CPUs share the same bus, same memory, and same I/O devices.
- Can be Heterogeneous (all CPUs are of the same hardware) or Homogeneous (each CPU has its hardware type or brand).
- Approaches to Multiple Processor Scheduling:
- Symmetric MultiProcessing. Each CPU is self-scheduling (has its own scheduler) and independent. The processes queue may be shared or each CPU has its own queue.
- Asymmetric MultiProcessing. There is one single CPU called the Master CPU that is responsible for running the OS and the schedular; while other CPUs only execute users’ processes. This is simpler than SMP.
- Processor Affinity. When a process runs on a CPU, it builds a cache and becomes affiliated with this CPU. Types of processor affinity:
- Soft Affinity: When the OS has the policy to keep the process on the same CPU but there is no guarantee.
- Hard Affinity: The Process will always run on the same CPU since it stores the CPU number in its PCB. The sched_setaffinity() sysCall allows the user to set the affinity of a process.
- Load balancing. The OS tries to balance the load of the processes on each CPU. It is only necessary for SMPs where each CPU has its own
private queue. There are two types of load balancing (process migration):- Push Migration: The OS runs a process that rottenly checks the load of each CPU and pushes the process to the CPU with the least load.
- Pull Migration: Idle CPUs pull processes from the CPU with the highest load.
- Multi-Core Processors:
- Multiple processor
coresare put together on a single chip. The core consists of a CPU, registers, and a cache. - It differs from Multi-Processor where each processor has its own chip.
- It is faster, cheaper, and more energy efficient than the traditional Multi-Processor.
- Multiple processor
- Memory stall. When a process is waiting for memory access, it is stalled. The OS can switch context to another thread until the response comes back.
- MultiThreaded processor cores. Each core gets assigned multiple threads at the same time. If one thread is stalled waiting for memory, the other threads can still run. There are two ways to process multithreading:
- Coarse-grained multithreading. A thread runs on a core until it is stalled. Then, the OS switch-context to another thread.
- Fine-grained multithreading. The switch between threads happens at a much finer level. The OS switch-context between threads every instruction cycle. Switching cost is lower than the cost of Coarse-grained multithreading.
Operating system - multi-threading 5¶
Thread¶
- A thread is a lightweight process.
- A thread is a part of a process. no thread can exist without a process.
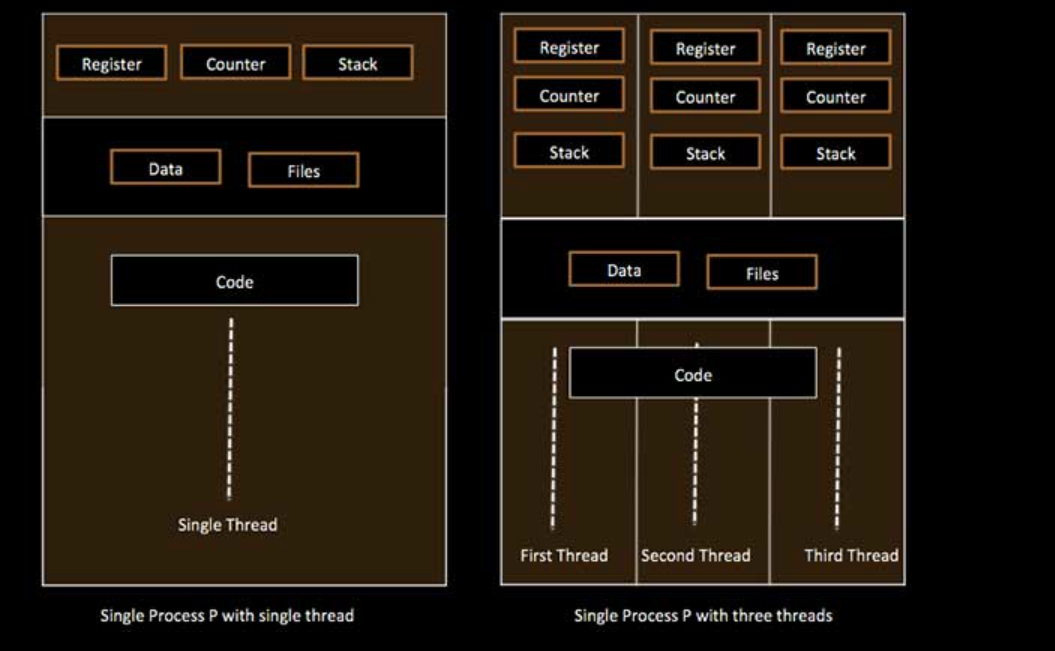
- Threads within the same process share the same heap (data segment), same code segment, and same open files. However, each thread has its own stack, registers, and program counter.
- Each thread represents a sequential flow of control within a process, and the threads within a process share the process’s resources.
- Threads enable parallelism and concurrency within a process.
| Process | Thread | |
|---|---|---|
| Definition | A process is an instance of a program that is being executed. | A thread is a unit of execution within a process. |
| Memory | Each process has its own memory space. | Threads share the same memory space within a process |
| context-switching | Context switching must be done by the OS. | Context switching may be done by the OS or a thread library within the process |
| resource consumption | A process consumes more resources than a thread. | Multiple threaded processes use fewer resources. |
| isolation | Processes are isolated from each other. | Threads are not isolated from each other, a thread can affect other threads within a process. |
- The Differences between single-threaded processes and multithreaded processes are shown below:
- Types of threads:
- User-level threads. The threads are implemented by the thread library within the process. The OS does not know about the threads. The context switching is done by the thread library.
- Kernel-level threads. The threads are implemented by the OS. The OS knows about the threads. Context switching is done by the OS.
Operating system - Process scheduling 6¶
- Categories of Scheduling:
- Process scheduling queues:
- OS maintains all process PCBs in a process scheduling queue.
- OS maintains a separate queue for each Process state.
- These queues include a job queue (which contains all processes in the system), a ready queue (which contains all processes that are ready for execution), and a device queue (which contains all processes awaiting I/O response.).
- Each queue has its own scheduling algorithm (FIFO, RR, Priority, etc.).
- Tow-State Process model:
- OS maintains two queues: a running queue and a not-running queue.
- Process scheduling queues:
CPU scheduling algorithms in operating systems 7¶
- burst time: The time required by a process for CPU execution. Only the time when the process is running on the CPU, excluding any waiting. aka. execution time.
- arrival time: The time at which a process arrives in the ready queue.
- waiting time: The time spent by a process waiting in the ready queue.
- response time: The time between the arrival of a process and the first response by the CPU. aka. When the process gets its first CPU round and then gives up CPU.
- turnaround time: The time between the arrival of a process and the completion of the process. Including all waiting time. aka. total time.
- internal timer. A Timer is built into the CPU. It is used to count the time that a process has been running on the CPU. It is used to implement the time slice.
- Dispatcher. A software module (part of the OS) that transfers control of the CPU to a process. It is responsible for context switching, switching to user mode, and moving to the correct location in the newly loaded process.
- CPU scheduling algorithms:
- First Come First Served (FCFS)
- Shortest Job First (SJF)
- Shortest Remaining Time First (SRTF)
- Priority Scheduling
- Round Robin (RR)
- Multilevel Queue Scheduling (MLQ)
Multithreading vs multiprocessing: What’s the difference 8¶
Advantages of Multiprocessing¶
- More work can be done in a shorter time.
- Easier Implementation.
- Uses multiple processors and cores.
- Child processes can be created and destroyed easily.
- Suitable when high speed is required to process a large amount of data.
- Saves power compared to single processor systems.
- Cons:
- Larger memory footprint.
- Inter-process communication (IPC) is more complex.
Advantages of Multithreading¶
- Threads are lightweight and have a small memory footprint.
- The cost of Inter-thread communication is less than Inter-process communication.
- Memory is shared between threads.
- Suitable for I/O intensive applications.
- Switching between threads is faster than switching between processes.
- Creating and destroying threads is faster than creating and destroying processes.
- Cons:
- The multithreading system is not interruptible or killable.
- Implementation is more complex.
References¶
-
Arpaci-Dusseau, R. H., & Arpaci-Dusseau, A. C. (2018). Operating systems: three easy pieces (1.01 ed.). Arpaci-Dusseau Books. Retrieved June 16, 2022, from https://pages.cs.wisc.edu/~remzi/OSTEP/. Chapter 9. ↩
-
Arpaci-Dusseau, R. H., & Arpaci-Dusseau, A. C. (2018). Operating systems: three easy pieces (1.01 ed.). Arpaci-Dusseau Books. Retrieved June 16, 2022, from https://pages.cs.wisc.edu/~remzi/OSTEP/. Chapter 10. ↩
-
Arpaci-Dusseau, R. H., & Arpaci-Dusseau, A. C. (2018). Operating systems: three easy pieces (1.01 ed.). Arpaci-Dusseau Books. Retrieved June 16, 2022, from https://pages.cs.wisc.edu/~remzi/OSTEP/. Chapter 13. ↩
-
Multiple processors scheduling in operating system. (n.d.). javaTpoint. https://www.javatpoint.com/multiple-processors-scheduling-in-operating-system? ↩
-
Operating system - multi-threading. (n.d.). tutorialspoint. https://www.tutorialspoint.com/operating_system/os_multi_threading.htm ↩
-
Operating system - Process scheduling. (n.d.). tutorialspoint. https://www.tutorialspoint.com/operating_system/os_process_scheduling.htm ↩
-
Williams, L. (2022a, July 9). CPU scheduling algorithms in operating systems. Guru99. Retrieved August 12, 2022, from https://www.guru99.com/cpu-scheduling-algorithms.html ↩
-
Williams, L. (2022b, July 9). Multithreading vs multiprocessing: What’s the difference? Guru99. Retrieved August 12, 2022, from https://www.guru99.com/difference-between-multiprocessing-and-multithreading.html#2 ↩