7. File Processing and External Sorting¶
Introduction 1¶
8.1 Primary versus Secondary Storage 1¶
- Primary Memory:
- Also called main memory.
- Provides random access to data (fast).
- Includes: registers, cache, video memory, RAM.
- Costs 100X more than secondary memory.
- It is volatile (loses data when power is lost).
- Access speed for 1 byte is of the order of 10 nanoseconds, regardless of data location (random access).
- Access speed is million times faster than secondary memory.
- Secondary Memory:
- Also called peripheral storage.
- Includes: hard disk drives, solid state drives, magnetic tape, DVDs, CDs, and USB drives.
- Costs 100X less than primary memory.
- It is Persistent (data is not lost when power is lost).
- It is more Portable as CDs, DVDs and USBs can be easily shared between computers.
- Access speed for 1 byte is of the order of 10 milliseconds, which may also depend on the location of the data on the disk.
- Access speed is million times slower than primary memory.
8.2 Disk Drives¶
- Logical file is a representation of a physical file in main memory as a contiguous sequence of bytes.
- Physical file is the actual file stored on the disk, which may be non-contiguous (spread across multiple locations on the disk).
- File Manager: is part of the operating system that:
- Manages the mapping between logical and physical files.
- When the file system receives read request to a logical location of a file (in relation to the beginning of the file), it translates the logical location to a physical location on the disk and fetches the data from the physical location.
- When the file systems receives a write request to a logical location of a file, it translates the logical location to a physical location on the disk and writes the data to the physical location, and updates file metadata accordingly.
- Direct Access: the ability to access any file location approximately as fast as any other location, Disk Drives provide direct access to data, but in practice, some locations are accessed faster than others.
- Sequential Access: locations are accessed in order (one after the other), Tape Drives provide sequential access to data, that is, to read logical location n+1, the locations 0 to n must be traversed first.
8.2.1 Disk Drive Architecture¶
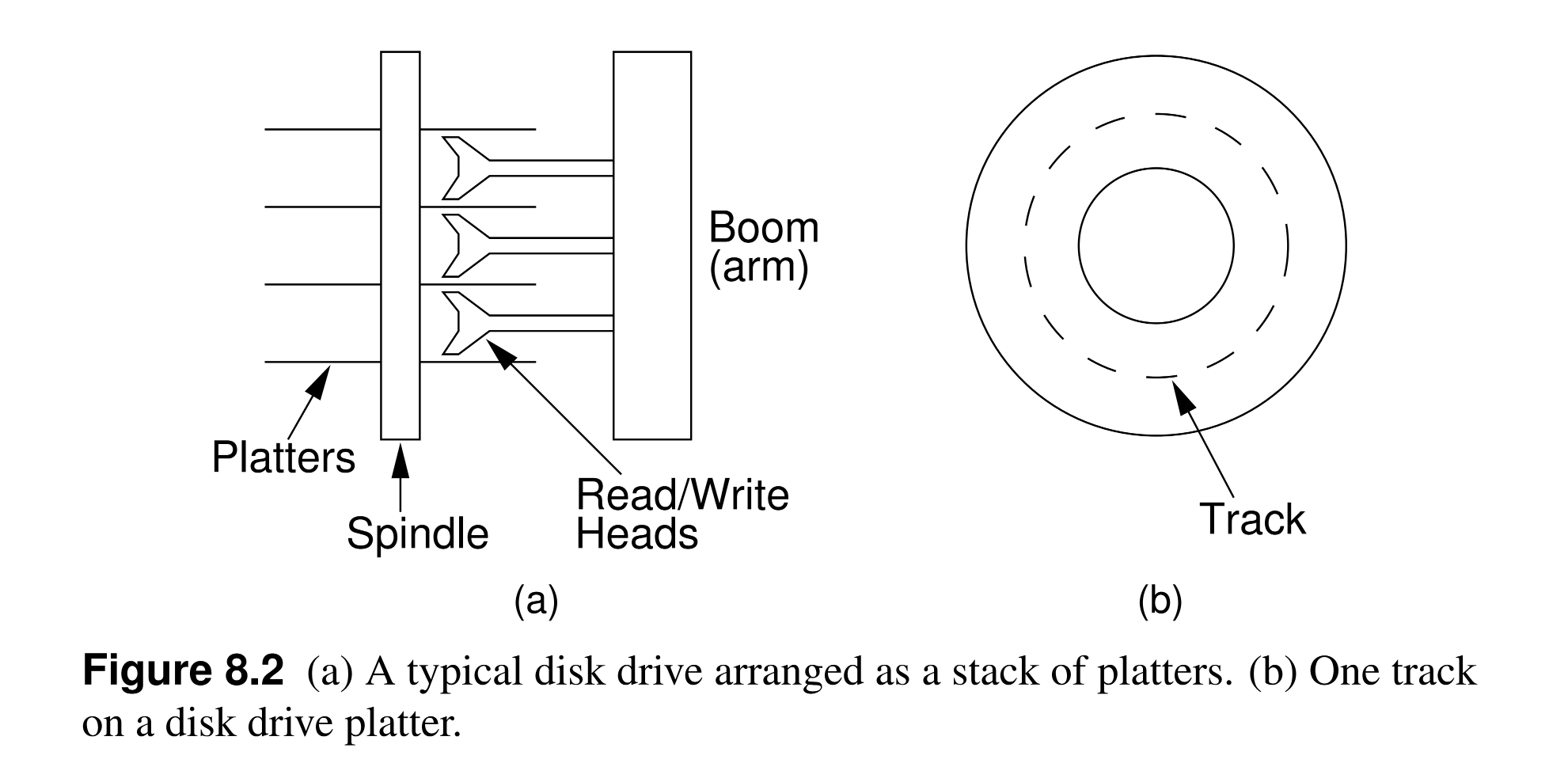
- Hard disk drives are consisted of Platters stacked on top of each other and attached to a central Spindle.
- Platters spin continuously at a constant speed (e.g. 7200 RPM).
- Each usable surface of each platter has a read/write Head that moves radially across the platter, but the head does not touch the platte’s surface.
- Each head is attached to an Arm that moves the head in and out (towards and away from the spindle).
- Then all arms are attached to a Boom.
- Track: a concentric circle on a platter that can be accessed by a head, that is, all data on a platter that have the same distance from the spindle.
- Cylinder: a set of tracks, one on each platter, that can be accessed by a head, that is, all data on all platters that have the same distance from the spindle.
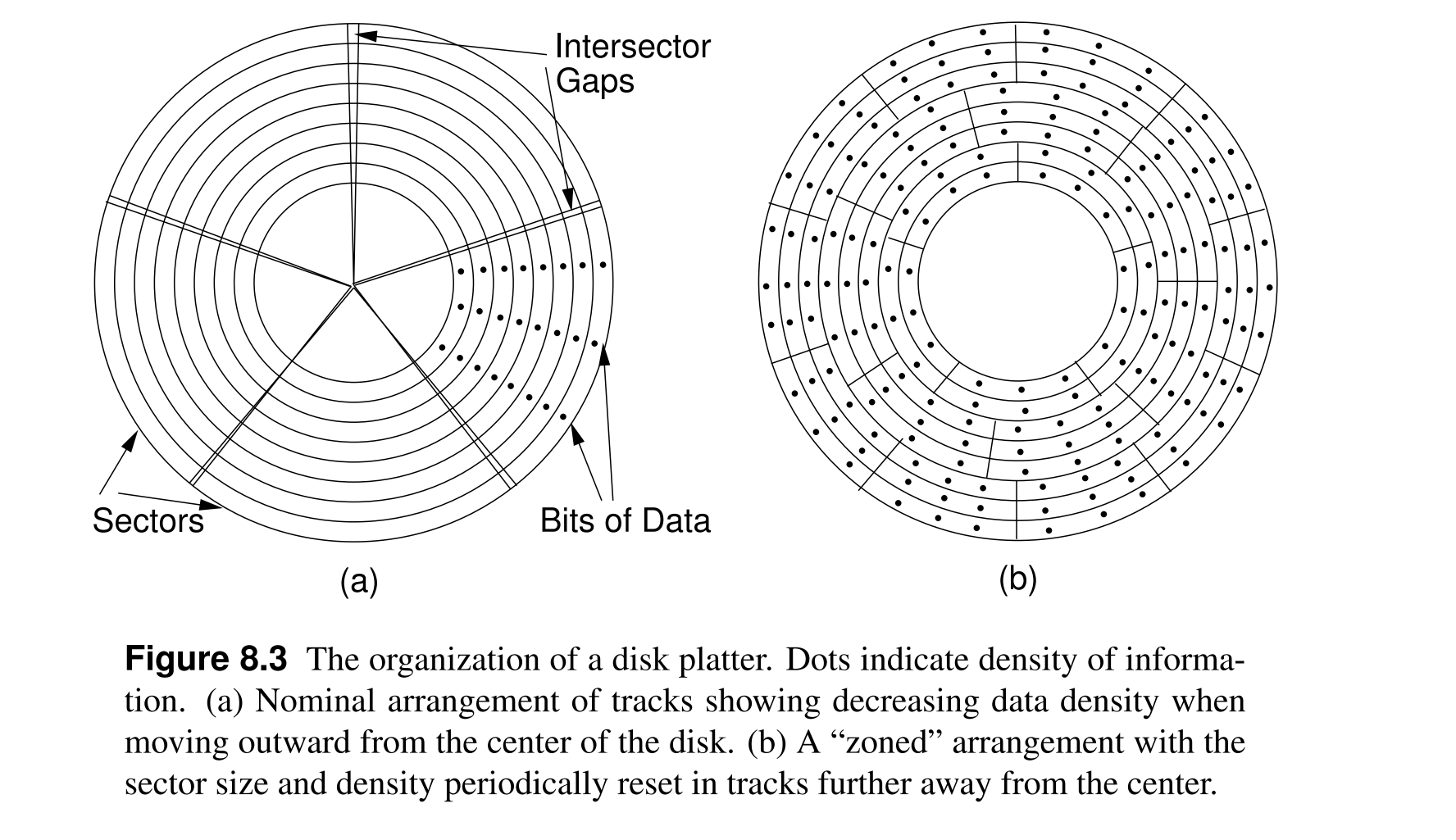
- Sector: a small section of a track, where sectors on a track are separated by inter-sector gaps in which no data is stored and their only purpose is to allow head to identify the boundaries of sectors.
- Historically, sectors where of the same size and each track holds the same number of sectors, that is, the innermost track has the same number of sectors as the outermost track, which means the gaps between sectors in the most outer tracks are larger than the gaps between sectors in the most inner tracks (see figure below, left).
- Nowadays, sectors are arranged into Zones, and outermost layers have more sectors than innermost layers, and the gaps between sectors are of the same size (see figure below, right) to better utilize the disk space.
- CD-ROMs architecture:
- CD-ROMS consist of a single platter forms a single spiral track, where bits are equally spaced along the track.
- Information density is the same no matter how distance from the spindle.
- Thus the spindle must alter its speed to maintain a constant data rate, speed is faster in the inner tracks and slower in the outer tracks.
- The I/O speed of a CD-ROM is slower than that of a hard disk drive.
- Reading a byte of a hard disk drive:
- Seek: Move the head to the correct cylinder (track), the slowest operation.
- Wait for the sector to rotate under the head: Rotational Latency.
- Transfer data: read or write the data, the entire sector is transferred, even if only a single byte is requested.
- Average hard disk rotates 7200 RPM.
- The minimum amount of data to be transferred is an entire sector.
- Ideally the data for one file should be stored in contiguous sectors, so that: seek time is minimized, rotational latency is minimized (locality of reference), and the entire file can be read in a single revolution of the disk.
- Clusters:
- Clusters only used in Windows operating systems.
- Cluster is a group of contiguous sectors that forms the minimum unit of allocation for a file, so that, all files are multiples of cluster size.
- Cluster size is determined by the OS.
- Clusters allocations to files are stored in a File Allocation Table (FAT), which stores data about which sectors belongs to which files.
- A group of contiguous clusters is called an Extent.
- Ideally, the file must be stored in one extent, but that depend on the existence of adjacent free clusters that are large enough to hold the file.
- Blocks:
- Blocks are used in Unix operating systems.
- Block is similar to cluster, which is the minimum unit of allocation for a file.
- UNIX stores information about which blocks belong to which files in i-nodes.
- Files are more fragmented when:
- The disk is nearly full, so the OS start storing files in any free space it can find.
- An old file is being extended (many files have taken the space that was adjacent to the file), so the OS start storing the new data in a distant free space.
- The more fragmented the files, the worse the seek time.
- If file sizes are not exactly multiples of the sector size, then the last sector of the file will be partially filled, which is a waste of space as some systems do not allow other files to use the remaining space in the sector.
- Internal Fragmentation: the wasted space in the last sector of a file, or the wasted space within a sector that is not used by the file.
- External Fragmentation: the wasted space between files, which translated to empty sectors entirely between files.
8.2.2 Disk Access Costs¶
- Seek time is the most significant factor in disk access time, and it is the time to move the head to the correct cylinder (track) which depends on the distance between the current cylinder and the target cylinder.
- Track to Track cost: the time to move the head from one track to the next track, which is the minimum time to move the head.
- Average Seek cost: the average time to move the head from one track to another track that is in a random distance from the current track.
- Most disks rotates at 7200 RPM, which means one round takes 16.7 ms to rotate over an entire track, and half that time to reach any sector in a track, thus 8.33ms.
- If the track has 16K sectors, then time for reading a single sector is 8.33ms/16K.
8.3 Buffers and Buffer Pools¶
- Buffer: a block of memory used to hold data temporarily.
- Once a request is issued to read/write to disk, the entire sector is read/written to the main memory (buffered), even if only a single byte is requested, as per the locality of reference, the other bytes in the sector are highly likely to be requested soon.
- Sector buffering is done by the operating system and it is built-in the disk drive controller hardware.
- Most Oses maintain two buffers: for input and for output.
- Double buffering: CPU read/write from/to one memory buffer, while the disk controller read/write from/to the other memory buffer in parallel.
- Page is the collection of information stored in a buffer, while the collection of buffers is called a buffer pool.
- The goal of buffer pool to reduce the number of disk accesses by storing the data that is most likely to be requested soon in the buffer pool.
- When the buffer pool is full, and a new page is requested, the page that is least likely to be requested soon is evicted from the buffer pool to make room for the new page.
- To decide which page to evict, different heuristics (approaches) are used:
- FIFO: first in first out.
- The page that was read first is evicted first.
- The buffer pool is implemented as a queue.
- Drawbacks:
- Programs usually uses the same pages over and over again, thus the page that was read first is likely to be read again soon.
- LFU: least frequently used.
- The page that was accessed the least number of times is evicted.
- The buffer pool is implemented as a priority queue where the priority is the number of times the page was accessed, thus the page with the lowest priority is evicted.
- Drawbacks:
- The page that is accessed more times is more likely to that the program has done with it and will not access it again.
- The overhead of maintaining the priority queue (updating the number of times a page is used).
- LRU: least recently used.
- The most used approach.
- The page that was accessed the longest time ago is evicted.
- It is implemented as a queue, where the page that was accessed most recently is at the front of the queue, and the page that was accessed least recently is at the end of the queue.
- The page at the end of the queue is always the one to be evicted.
- FIFO: first in first out.
- Writes operations are committed to the buffer pool, and then the buffer pool is committed to the disk on a specific time, as:
- When the file is closed (guarantee no more edits to the block/page).
- When the page that contains the block is evicted from the buffer pool (There might be more edits to the block, but that will involve bringing the block back to the buffer pool before editing it).
- Each page in the buffer pool has a dirty bit that indicates whether the page has been modified since it was read from the disk, when the page is evicted, if the dirty bit is set, then the page is written back to the disk, otherwise, it is just flushed away and the space is reused.
- Virtual memory:
- It is technique that allows the OS to use the disk as an extension to the main memory, so that, the OS can load the most frequently used pages in the main memory, and the least frequently used pages in the disk, and when a page is needed, the OS will swap it with a page in the main memory.
- Virtual memory uses the Buffer Pool technique to keep pages that are most likely to be used in the main memory.
Buffer Pool Implementation¶
- Two basic approaches regarding the transfer of information between the user and the buffer pool:
- Message passing: the user sends a message to the buffer pool to read/write a specific page.
- Buffer Passing: the user gets direct access to the buffer pool’s pointers.
- Message PAssing:
insert()andgetbytes()are the two methods that the user can use to read/write to the buffer pool.posis the logical position in the buffer pool logical space; the physical position is calculated by the supportive system calls.
/** ADT for buffer pools using the message-passing style */
public interface BufferPoolADT {
/** Copy "sz" bytes from "space" to position "pos" in the buffered storage */
public void insert(byte[] space, int sz, int pos);
/** Copy "sz" bytes from position "pos" of the buffered storage to "space". */
public void getbytes(byte[] space, int sz, int pos);
}
- Buffer Pool Pointers:
- The user supplies a pointer to a buffer from the buffer pool that holds the block/page that the user wants to read/write.
- The user must manually copy the data from/to the buffer.
- The problem of Stale Pointers may appear, where the buffer (within the supplied location) is evicted and and replaced with the content of another block/page, thus the pointer is no longer valid, but the user still having it referencing the old block/page.
- To avoid stale pointers, the user/client must lock the buffer pool while doing the read/write operation, and release the lock once finished.
- The
acquireBufferandreleaseBuffermethods are used to lock and unlock the buffer pool by increasing/decreasing the lock counter, respectively. - Any buffer that has a lock counter greater than zero is not evicted from the buffer pool.
- Another problem may arise, if all buffers are locked, then one more buffer is needed, but all buffers are locked, thus the user must wait until a buffer is unlocked.
- But, what if users/clients are not releasing the buffers? Deadlock may occur.
/** ADT for buffer pools using the buffer-passing style */
public interface BufferPoolADT {
/** Return pointer to the requested block */
public byte[] getblock(int block);
/** Set the dirty bit for the buffer holding "block" */
public void dirtyblock(int block);
// Tell the size of a buffer
public int blocksize();
};
- Improved Buffer Pool Implementation:
/**
* Improved ADT for buffer pools using the buffer-passing style.
* Most user functionality is in the buffer class, not the buffer pool itself.
*/
/** A single buffer in the buffer pool */
public interface BufferADT {
/** Read the associated block from disk (if necessary) and return a pointer to the data */
public byte[] readBlock();
/** Return a pointer to the buffer’s data array (without reading from disk) */
public byte[] getDataPointer();
/** Flag buffer’s contents as having changed, so that flushing the block will write it back to disk */
public void markDirty();
/** Release the block’s access to this buffer. Further accesses to this buffer are illegal. */
public void releaseBuffer();
}
/** The bufferpool */
public interface BufferPoolADT {
/** Relate a block to a buffer, returning a pointer to a buffer object */
Buffer acquireBuffer(int block);
}
- The message passing approach is more preferable than the buffer passing approach, because it is more secure and less error-prone.
- The buffer passing approach puts more obligations on the user/client:
- User/client myst know the size of the block/page.
- User/client must not corrupt the pool’s storage space.
- User/client must notify the pool when the block/page is modified and when it is no longer needed.
- But the buffer passing approach is more efficient as it avoid extra copying of the data when transferring it the user/client to the buffer pool.
- If records’ size are small, the extra copying by the message passing approach is not a big deal, but if records’ size are large, then the extra copying is a problem and the buffer passing approach is more preferable.
8.4 The Programmer’s View of Files¶
- The programmer sees a file as a single stream of bytes where the following operations can be performed:
- Read bytes from the current position in the file.
- Write bytes to the current position in the file.
- Move the current position in the file.
- The programmer does not know about how the bytes are stored in sectors, clusters, blocks, or pages.
- The programmer does not know about the physical addresses of the bytes in disk as sector-level buffering is done automatically by the disk controller.
- The java language provided the
RandomAccessFileclass to implement the programmer’s view of files that has the following methods:RandomAccessFile(String name, String mode): opens a file with the given name and mode.read(byte[] b)reads bytes from the file into the given array, the current position is moved forward by the number of bytes read.write(byte[] b)writes bytes from the given array into the file, the current position is moved forward by the number of bytes written.seek(long pos)moves the current position to the given position.close()closes the file.
8.5 External Sorting¶
- External sorting is a techniques used to sort large collections of data that cannot fit in the main memory, and thus must be stored in the secondary memory (disk).
- External Sorting is opposite to the internal sorting, where the data is assumed to be all loaded in the main memory.
- The practical way of external sorting:
- Move some data from the disk to the main memory, sort them, and write them back to the disk.
- Repeat the previous step until all data is sorted.
- This process reads records multiple times until they are sorted.
- The primary goal of external sorting is to minimize the number of disk accesses or writes and do as much work as possible in the main memory.
- Assumptions for external sorting algorithms:
- The file is stored as a series of fixed-size blocks.
- Each block contains the same number of fixed-size records.
- The records may be of few bytes or a few hundred bytes.
- Records do not cross block boundaries.
- External sorting specifications:
- The minimum unit of I/O is the sector, which ranges from 512 bytes to 16k bytes (powers of 2).
- The block size is a multiple of the sector size.
- The entire block is read to the main memory, stored into a buffer in the pool, and then processed as a unit.
- The content of the single block -in memory- is sorted using an internal sorting algorithm.
- To avoid the time-consuming seek time, the blocks are read sequentially from 0 to N-1, where N is the number of blocks in the file, but we should be aware that sometimes random access is faster than sequential access.
- The sequential access is faster when the number of extent is very small (close to 1), which means that all blocks are stored in a contiguous area in the disk; thus, writhing the file to the disk at once gives faster sequential access as data are more likely to be stored in the same extent.
- The disk head may be positioned exactly on the track of the target file, that is, no other user/program is using the disk, thus the disk head is not moving to other tracks (files).
- Key Sort: to minimize reading/writing to the original record-heavy file, the keys of each record is indexed in a separate file including the record’s location, then keys are sorted, and the original file kept as it is.
8.5.1 Simple Approaches to External Sorting¶
- Usually, the disk size is much larger than the virtual memory (including the main and swap memories), thus the disk is used to store the data that cannot fit in the virtual memory.
- If your data can fit in the virtual memory, then you can use the internal sorting algorithms, as:
- Load the file into the virtual memory (main memory + swap memory) as it is automatically manages the buffer pool to efficiently read/write data from/to the swap memory.
- Apply a normal internal sorting algorithm, such as QuickSort, MergeSort, or HeapSort.
- Quick sort is not a good choice for external sorting, because:
- Quick sort requires random access to the data, which is expensive as it requires more I/O operations.
- Quick sort must access each item at leas log N times, along with the overhead of the partitioning process and the cost of I/O operations.
- Quick sort will use most of the system resources (the entire virtual memory, and CPU).
- Merge sort may be a better choice as it takes advantage of the double buffering technique, and handles each block as a unit (not as individual records).
- Load as many blocks as possible into the main memory, sort them using the merge sort algorithm, and write them back to the disk to an output file, and repeat the process until all blocks are sorted into the output files.
8.5.2 Replacement Selection¶
- Replacement Selection is a variation of Heap Sort, that builds longer runs which reduces the total number of I/O operations.
- It reads memory as continuous array of size M, one record is processed at a time and moved to the output buffer; exactly one replacement record is imported from the input buffer to the algorithm’s memory, and if input buffer is empty, a new block is read from the disk to the input buffer to be processed record by record.
- Steps:
- Initially, the algorithm reads M records from the input buffer to the its memory, and it builds a Min Heap where the smallest record is at the root of the heap.
- Send the root of the heap to the output buffer (sorted file), and replace it with the next record from the input buffer and re-heapify the heap.
- If the next element is greater than the
previous root, re-heapify the heap, and output the root to the output buffer, then import a new record from the input buffer. - If the next root is smaller than the
previous root, we can not be sure about its position in the sorted file, so we keep it in a special place (at the end of the array, outside of the heap), and we import a new record from the input buffer. - The elements that set in the special place will be processed again in the next run.
- A record is added to the heap until no more records are available in the input buffer (and the file itself).
- The total length of the runs is twice the length of the array M, as long as inputs are randomly distributed.
8.5.3 Multi-way Merging¶
- After building the runs using the replacement selection algorithm, we need to merge them into a single sorted file.
- We used the default two-way merging technique: as the two runs already sorted, look at the first element of each run (sub-array), and output the smallest one to the output, then import a new element from the run that the smallest element was outputted from; then repeat until all elements are sorted in the output array (run).
- Multi-way merging is a generalization of the two-way merging, where we have B runs to merge (B > 2), where the algorithm checks the first element of each run, and output the smallest one to the output buffer, then import a new element from the run that the smallest element was outputted from; then repeat until all elements are sorted in the output array (run).
- Total cost:
- Replacement Selection builds runs in one pass.
- Multi-way merges the runs in one pass (as long as there is place in memory for one block of each run).
References¶
-
Shaffer, C. (2011). A Practical Introduction to Data Structures and Algorithm Analysis. Blacksburg: Virginia. Tech. https://people.cs.vt.edu/shaffer/Book/JAVA3e20130328.pdf. Chapter 8: File Processing and External sorting. ↩↩