DA8. Web Crawler Architecture
Statement¶
What steps are involved in designing the architecture for a web crawler? How can you ensure the web crawler properly indexes the content of a website?
Solution¶
Task 1: Crawler Architecture¶
In the previous assignment, discussion assignment 7, we discussed the main components and processes of a web crawler; and the following diagram shows the main components and processes of a web crawler (Gautam, 2023):
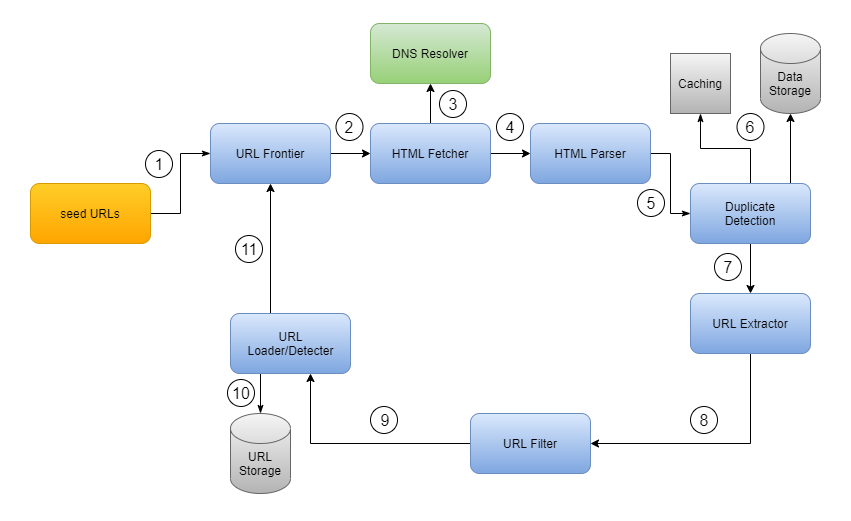
The purpose of this assignment is to discuss the decisions that led to that architecture and the steps involved in designing it.
According to (Manning et al., 2009), the following steps are involved in designing a web crawler:
- The URL Frontier.
- DNS Resolution.
- Fetch Module.
- Parsing Module.
- Duplicate Detection.
The architecture described by (Manning et al., 2009) is similar to the one described by (Gautam, 2023), with the latter putting some sub-components under their own modules, thus it involved more components and processes.
Manning also discussed some issues with that architecture; for example, when should the crawler decide that it should not fetch a page? such a decision can be made at two stages:
- Before fetching the page: We consult the robots.txt and other policies, to decide if we should fetch the page. This is helpful if the URL was already added to the URL frontier and the robots.txt changed since then.
- After fetching the page: On the parsed links, we do the filtering on those URLs, and only the URLs that pass the filter are added to the URL frontier.
Some more housekeeping processes also run in the background as part of the crawler (Manning et al., 2009):
- Every few seconds, log crawl progress statistics (URLs crawled, frontier size, etc.).
- Decide if the crawler should stop.
- Every few hours, checkpoint the crawl, a snapshot of the crawler’s state (say, the URL frontier) is committed to disk.
- In case of a crash, the crawler can be restarted from the last checkpoint.
Task 2: Properly Indexing a Website¶
Indexing a website is a complex process where crawlers and indexers work together to make sure that all useful content is indexed and served to the end-users upon request. Before indexing the following steps are performed (Manning et al., 2009):
- All the pages on that website are crawled, and the content is extracted, parsed, and stored in raw form.
- Link Analysis is performed on the crawled pages to determine the importance of each page and the importance of each link.
- The usual indexing process is performed, and term/document weightings, rankings, and other statistics are computed considering the link analysis results.
As part of the link analysis, the in-links and out-links of each page are computed, then the anchor text terms of each link are extracted and added to the terms of the page (although marked separately from the terms of the page itself). The PageRank, authority, and hub scores are computed for each page.
Putting all of that in mind, it is possible to return a page to the query computer, although the page itself does not contain the term. However, some links that point to that page contain the term computer in their anchor text, and the page has high PageRank, authority, or hub scores.
References¶
- Gautam, S. (2023). Web Crawler System Design. Enjoyalgorithms.com. https://www.enjoyalgorithms.com/blog/web-crawler
- Manning, C.D., Raghaven, P., & Schütze, H. (2009). An Introduction to Information Retrieval (Online ed.). Cambridge, MA: Cambridge University Press. Chapter 20: Web crawling and Indexes. http://nlp.stanford.edu/IR-book/pdf/20crawl.pdf