Data Models¶
1. Introduction 1¶
- DBMS. A database-management system (DBMS) is a collection of interrelated data and a set of programs to access those data.
- Database. A database is a collection of related data.
- Before DBMS, data was stored in files, and file-processing systems were used to access the data, but these systems have a number of disadvantages:
- Data redundancy and inconsistency.
- Difficulty in accessing data.
- Data isolation: files may have different formats that are not compatible with each other, which isolates information stored in them from the rest of the system.
- Integrity problems: difficult to apply integrity constraints.
- Atomicity problems: difficult to ensure that a transaction is atomic; upon failure, the whole transaction must be rolled back to the state before the transaction started.
- Concurrent access problems: difficult to ensure that concurrent transactions do not interfere with each other.
- Security problems: difficult to ensure that only authorized users can access only the data they are authorized to access.
- DBMSs solve most of the problems mentioned above.
1.3 View of Data¶
- a major purpose of a DBMS is to provide an abstract view of data while hiding the details of how these data are stored and accessed.
- Data abstraction:
- Physical layer: describes how the data are stored and the complex low-level data structures that are used to store data. Used by DBMS developers.
- Logical layer: describes what the data are and the relationships among them. Used by DBAs.
- View Level: the highest level of abstraction, describes only part of the entire database. Used by end users.
- Instances and schemas:
- Instance: the collection of information stored in the database at a particular moment. Frequently changed.
- Schema: the overall design of the database is called the database. Infrequently changed. Every layer has its own schema:
- Physical schema: describes the schema at the physical level.
- Logical schema: describes the schema at the logical level. This is the most important one since it is the one we interact with as DBAs or programmers.
- View schema: also called subschema, describes the schema at the view level, which varies according to the view of the data that is required by the user.
1.4 Data Models¶
- The Data model, is a collection of conceptual tools for describing data, data relationships, data semantics, and consistency constraints. models:
- Entity-Relationship (ER) model.
- Relational model.
- Object-oriented model.
- Object-relational model.
- Semi-structured data model.
- ER model:
- ER is based on the concept of entities and relationships among entities.
- An entity is an object or thing that maps to a real-world object. Entities have attributes, which are properties of the entity.
- A relationship is an association among entities. For example, a depositor is a relationship between a customer with his/her account.
- Entity set. is a collection of entities of the same type. Relationship set. is a collection of relationships of the same type.
- ER Diagram:
- Rectangles: entity sets.
- Ellipses: attributes.
- Diamonds: relationship sets.
- Lines: connect entities to attributes, and relationships to entities.
- Relational model:
- The relational model is based on the concept of relations (or tables) where each table has columns (attributes) and rows (tuples).
- The relational model is lower level than ER Model; that’s why DB designs are carried out in ER model and then translated to the relational model.
- Object Oriented model:
- Extends the ER model with notions of encapsulation, methods, and object identity.
- Object-relational model:
- Combines relational and object-oriented models.
- Semi-structured data model:
- Allows items of the same type to have different attributes; in contrast with the other models, where all items of the same type must have the same attributes.
- Extensible markup language (XML) is an example of a semi-structured data model.
- Other data models:
- Network data model.
- Hierarchical data model.
- The two models above are not widely used, since they were closely tied to the underlying implementation and made data modeling difficult.
1.5 Database Languages¶
- Data Definition Language (DDL):
- Defines the database schema, where it creates/modifies table structure and updates DBMS metadata.
- DDL contains:
- Data storage definition.
- Consistency constraints.
- Data Manipulation Language (DML):
- Includes: Retrieve, Insert, Update, Delete.
- DML has 2 types:
- Procedural DMLs: user must specify what data is needed and how to get it.
- Declarative DMLs: user only specifies what data is needed, and the DBMS decides how to get it.
- SQL is an example of a declarative DML.
- A query is a statement written in a Query Language to retrieve data from a database.
- Application programs are programs that are used to interact with the database. Application programs are usually written in a host language, such as Cobol, C, C++, or
Java. 2 ways to interact with the database:
- API: The DBMS provides sets of procedures (APIs) that applications can use to send DDL and DML statements to the DBMS. examples: JDBC (java), ODBC (c lang).
- Extending the host language, The DBMS provides a precompiler that translates the host language statements into DBMS statements.
- Database Users:
- Naive users are usually the end-users, who invoke application programs that in turn invoke the DBMS. end users.
- Applications programmers are programmers who write application programs that use the DBMS. developers
- Sophisticated users are programmers who write programs that use the DBMS to access data directly, they interact with the query processor directly. analysts
- Specialized users are sophisticated users that write special DBMS programs or non-traditional applications that use the DBMS. DBAs
1.6 Transaction management¶
- Atomicity, all or none, if one operation fails, the whole transaction must be rolled back. Integrity.
- Consistency, the database must be in a consistent state before and after the transaction. Correctness.
- Durability, once a transaction is committed, the changes made by the transaction must be permanent. Persistence.
- Ensuring the atomicity, consistency, and durability of a transaction is the responsibility of the database itself (transaction manager component).
- Failure Recovery, the database must detect failures and restore its state before the failure occurred.
- The concurrency control manager component of the DBMS ensures that the database is in a consistent state even when multiple transactions are executed concurrently.
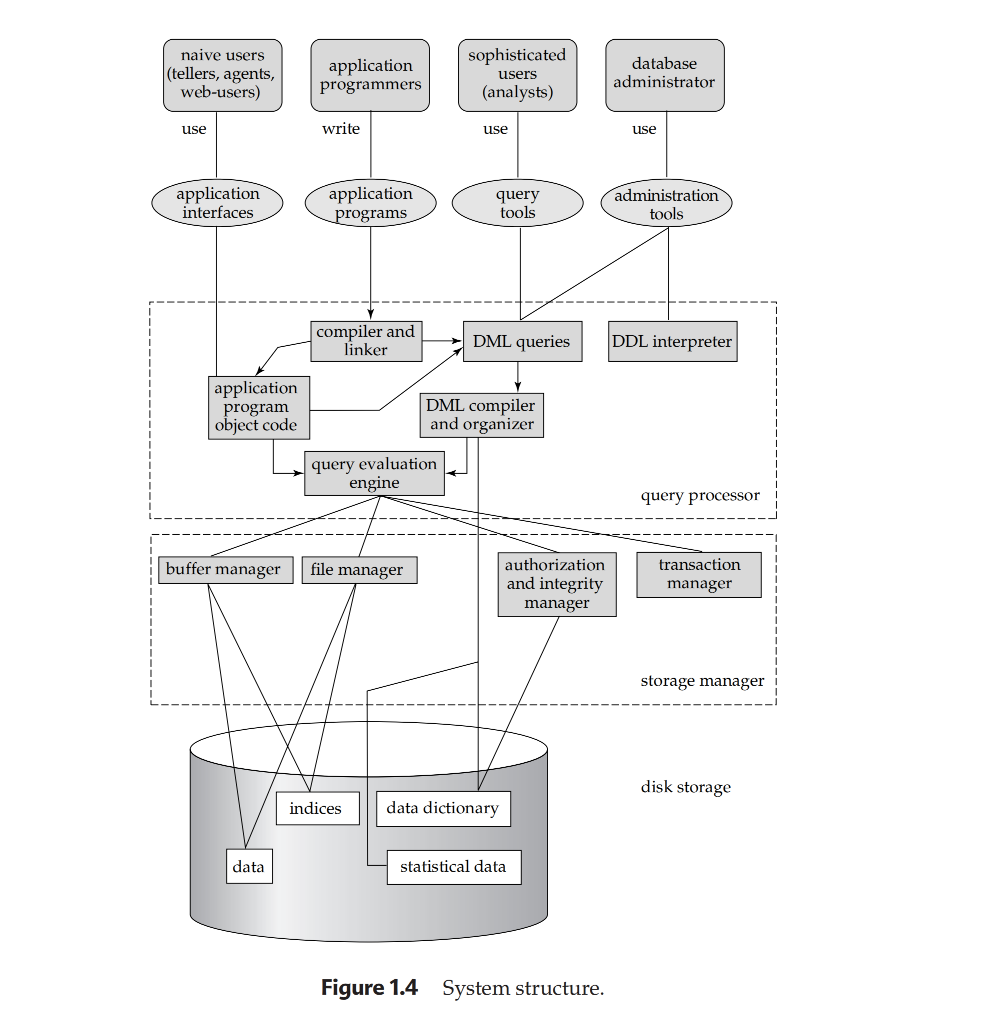
1.7 Database system architecture¶
- The database system is portioned into modules each performing a set of tasks.
- The main two components are the storage manager and query processor.
- Storage manager:
- Provides an interface between the low-level data stored in DB and application programs or queries submitted to the system.
- Interacts with the file manager which stores data on disk using the OS file system.
- Translates DML statements into low-level file system commands.
- Responsible for storing, retrieving, and updating data.
- Components:
- Authorization and integrity manager. checks for authority and integrity constraints.
- Transaction Manager. ensures that transactions are atomic, consistent, and durable along with failure recovery.
- File manager. manages the physical storage of data on disk along with the data structures that represent this data.
- Buffer manager. manages the memory and decides which data to cache in memory versus which data to store on disk.
- Data Structure:
- Data Files. the files that store the actual data.
- Data Dictionary. contains metadata about the database.
- Indices. are data structures that speed up data retrieval.
- Query Processor:
- Translates queries into low-level commands that the storage manager can execute.
- Components:
- DDL interpreter.
- DML compiler translates DML statements written in a query language into an evaluation plan consisting of low-level instructions that the query evaluation engine can understand.
- Query Optimizer. determines the best way to execute a query.
- Query Evaluation Engine. executes the evaluation plan.
1.8 Database History¶
- 1950s-1960s:
- Magnetic tapes or Punch cards were used to store data.
- Reading data must be done sequentially.
- 1970s:
- Hard disks were introduced.
- Sequential access was replaced by random access from hard disks.
- The Relational model was introduced.
- 1980s:
- The relational model was implemented in DBMSs.
- Relational databases were so easy to use that they eventually replaced network/hierarchical databases.
- 1990s:
- SQL was introduced to support decision support applications, which are query intensive as opposed to transaction processing applications which are update intensive.
- Distributed and parallel databases were introduced.
- Adapt to the Internet (no downtime for maintenance, no single point of failure, higher transaction rates, etc.).
2. Entity-Relationship Model 1¶
- Concepts:
- Entity set; contains many entities that may be concrete (real-life object, eg, person, car) or abstract (intangible, conceptional, eg, loan, holiday, concept).
- Entities have attributes.
- Each attribute has a value from a domain.
- Entities participate in relationships.
- A relationship instance is a relationship between two entities (not between entity sets, eg, person1 with loan 502).
- Entities have roles in relationships.
- Recursive relationships are when an entity set participates in a relationship more than once in different roles, e.g, a manager is an employee and a manager.
- Relationship Degree is the number of entities participating in a relationship, eg, binary, ternary..etc.
- Attribute characters:
- Simple or Composite (composed of more than other attributes), eg, the
nameis a composite attribute composed of first name and last name. - Single-valued or Multi-valued, eg, the
nameis single-valued, but thephone numberis multi-valued (one person can have more than one phone number, list). - Derived, eg, the
ageis derived from thedate of birth, we do not store the age, we calculate it from the date of birth.
- Simple or Composite (composed of more than other attributes), eg, the
- Constraints:
- Cardinalities represent the number of entities that another entity can associate with the relationship.
- Total participation, between entity set (E) and a relationship set (R) if every single entity from E participates in R. otherwise it is a partial participation.
- super key is a set of one or more attributes that uniquely identify an entity in the entity set.
- Keys:
- Primary Key is the candidate key chosen by the DB designer to serve as a unique identifier.
- candidate keys are a combination of keys that together can uniquely identify an entity; no single key of the candidate keys is a super key on its own.
- Weak Entity set:
- An Entity set that does not have enough attributes to form a primary key and can not exist on its own.
- A weak entity belongs to another strong entity (owner or identifying entity) through an identifying relationship as many-to-one from the weak entity to the owner entity.
- Example: LoanPayment is a payment that does not exist without a loan, so it is a weak entity belonging to a Loan.
- The Discriminator or Partial Key is an attribute within the weak entity set that uniquely identifies each entity within the relationship with the owner entity.
- Example: A Loan has multiple payments, but each has a PaymentNumber discriminates between individual payments for that loan.
- Extended ER features:
- Specialization:
- Group entities within a set when they have distinct attributes.
- Example: A Person can be specialized as a Customer or Employee.
- Represented by a triangle in the ER diagram.
- Used in a top-down approach.
- Generalization:
- Used in a bottom-up approach.
- Types of generalizations:
- Attribute-defined generalization, one attribute distinct between the entities, eg,
account typeis a discriminant betweencheckingandsavingsaccounts. - User-defined generalizations, may or may not be, aka. optional, eg,
employee teamsince not all employees are part of a team; theTeamis a generalization of a list of Employees.
- Attribute-defined generalization, one attribute distinct between the entities, eg,
- Specialized entities can be:
- DisJoint, an entity can only belong to one specialization. eg,
checkingorsavingsaccounts but not both. - Overlapping, an entity can belong to more than one specialization. eg, a
Usercan be both aCustomerand anemployee.
- DisJoint, an entity can only belong to one specialization. eg,
- Attribute inheritance
- All attributes of higher-level entities are inherited by lower-level entities by default.
- Aggregation:
- Aggregation is an abstraction through which relationships are treated as higher-level entities.
- Specialization:
- ER Limitations:
- It cannot express relationships among relationships.
- Unified Modeling Language (UML):
- Class Diagram.
- Use Case Diagram.
- Activity Diagram.
- Implementation Diagram.
- ER notations:
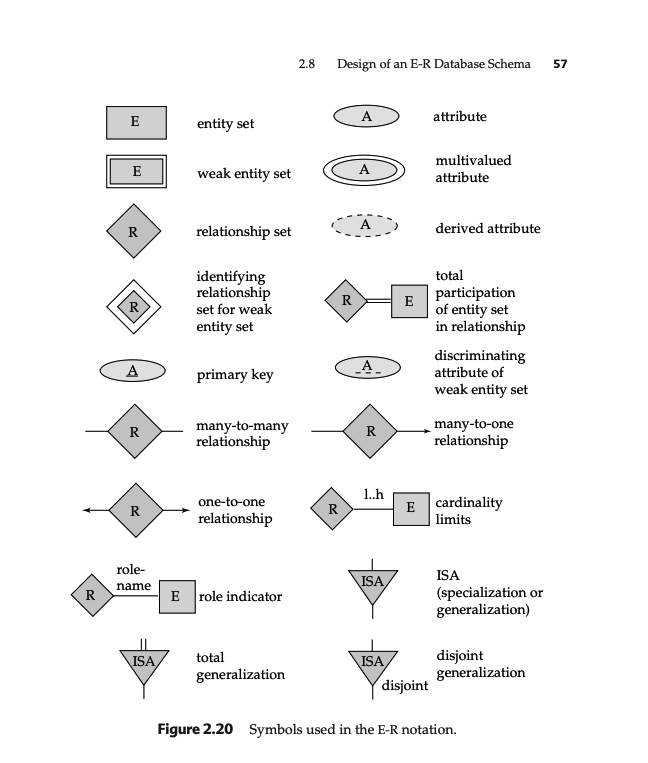
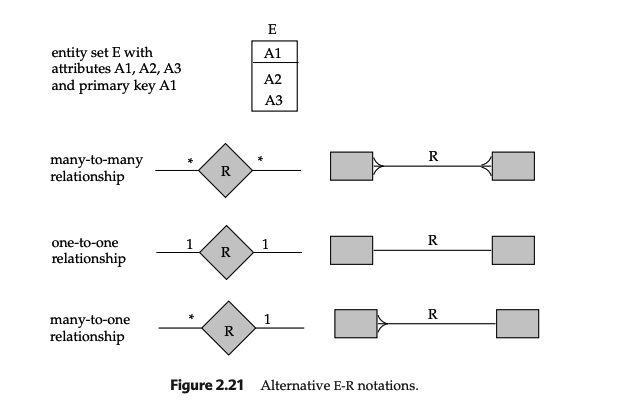
3. Relational Model 1¶
- Structure:
- Tuples (rows) and Attributes (columns) are saved into Relations (tables).
- Each attribute has a domain that must be atomic (cannot be decomposed into smaller parts).
- The Null value indicates that the value is unknown or does not exist.
- Database Schema is the logical design of a database, while Database Instance is a snapshot of the database at a particular time.
- If an attribute is a foreign key (FK), it must be a primary key (PK) in another relation called the referenced relation.
- Schema Diagram Example:
- The Schema Diagram is a graphical representation of the database schema. it differs from the Entity-Relationship Diagram in that it shows the foreign keys explicitly.
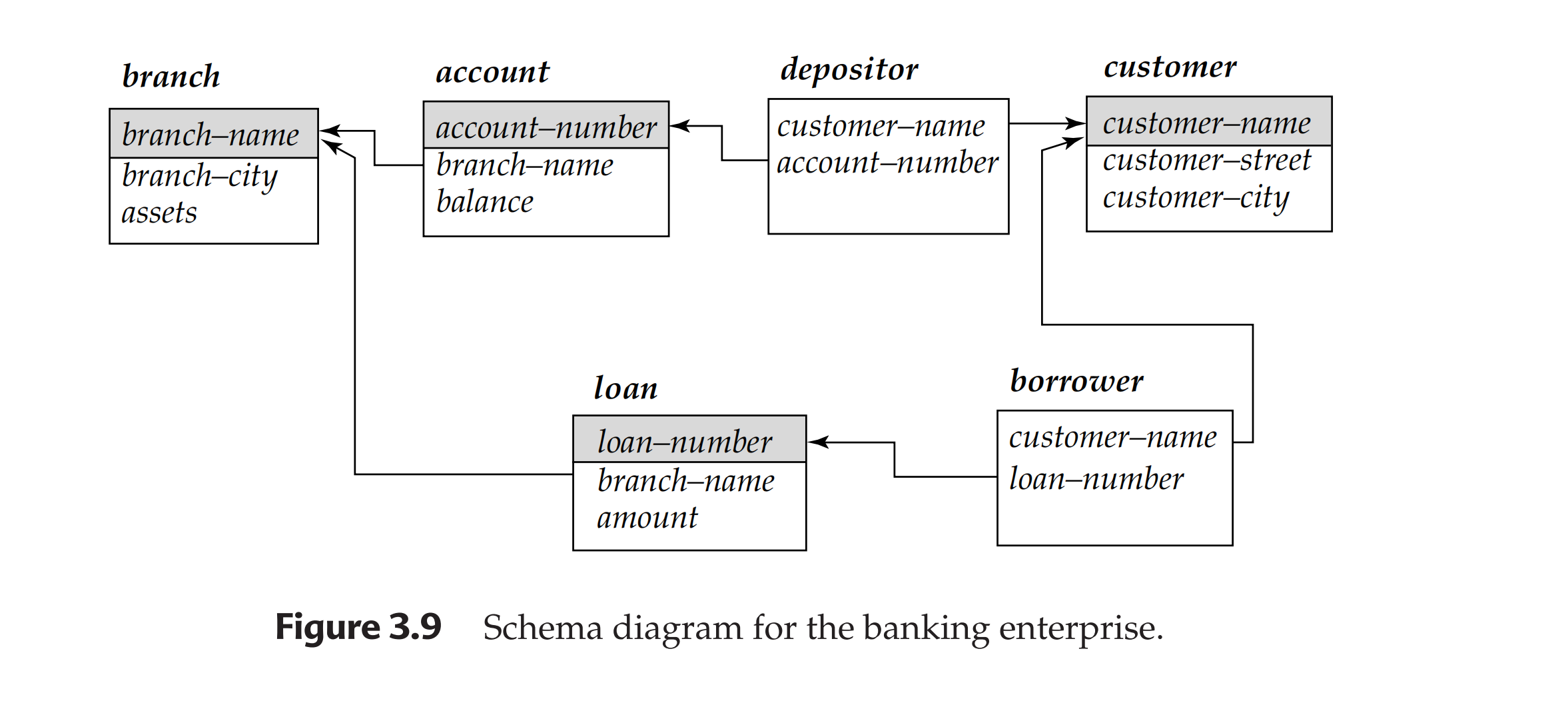
3.1.5 Query Languages¶
- Query Languages:
- Relational algebra (eg, SQL) - procedural.
- Tuple relational calculus - non-procedural.
- Domain relational calculus (eg, QBE language) - non-procedural.
Relational Algebra¶
- Relational Algebra is a procedural query language that is used to query a relational database.
- It consists of a set of operations that take one or two relations as input and produce a new relation as output.
- Unary operations are operations that operate on one input set while binary operations expect a pair of sets as an input.
- Relational Algebra operations:
- Fundamentals Operations:
- Select.
- Project.
- Union.
- Set Difference.
- Cartesian Product.
- Rename.
- Other operations:
- Set Intersection
- Natural Join.
- Division
- Assignment
- Fundamentals Operations:
- arity is the number of attributes in a relation.
- Compatible relations are relations that satisfy the following conditions:
- They have the same arity (same number of columns).
- Each of their attributes must be of the same domain.
| Operation | type | symbol | function | Notes |
|---|---|---|---|---|
| Select | unary | sigma (σ) | selects tuples that satisfy a given predicate | |
| Project | unary | pi (Π) | selects specific attributes from a relation | |
| Union | binary | U | returns tuples that are in either relation | input relations must be compatible |
| Set Diff | binary | - | returns tuples that are in the first relation but not in the second relation | input relations must be compatible |
| Cartesian Product | binary | X | returns all possible combinations of tuples from both relations (each elem from r1 is mapped to every element from r2) | input relations must have unique names, returns big operation with r1 * r2 tuples |
| Rename | unary | rho (ρ) | returns the same relation at a different name | |
| Intersect | binary | cap (⋂) | returns tuples that are in both relations, r1 ⋂ r2 = r1 - ( r1 - r2) | input relations must be compatible |
| Natural Join | binary | join (⋈) | performs a conditional selections on the cartesian product and returns subset of the CP that matches the conditions |
- Aggregate functions take a collection of values and return a single value as a result.
- Aggregate functions:
- Sum.
- Avg.
- Count.
- Min.
- Max.
3.3.4 Null Values¶
- Null values are used to represent unknown or missing values.
- If a null value is entered in an arithmetic expression or logical expression, the result is always unknown; since we can not decide a result.
- Boolean operations with unknown values work as:
| first argument | Operation | second argument | Result |
|---|---|---|---|
| unknown | AND | unknown | unknown |
| true | AND | unknown | unknown |
| false | AND | unknown | false |
| unknown | OR | unknown | unknown |
| true | OR | unknown | true |
| false | OR | unknown | unknown |
| unknown | NOT | - | unknown |
3.5 Views¶
- Views are virtual tables that are defined by a query.
- Views values are not stored in the database, they are computed on the fly.
- Materialized views are views that are stored in the database, they are updated when the underlying tables are updated.
- Update or insert operations on a view are not allowed, they can only be performed on the underlying tables.