WA5. Building an IR System - Part 3¶
This text is divided into three parts, starting from my code in the previous assignment:
- Statement: Includes the statement of the assignment, formatted in an easy-to-follow format.
- Summary: description of the assignment, my observations, and final notes. 0.
- Changes: A step-by-step documentation of all my interactions and changes to the code.
Statement¶
In the previous two development assignments, we created a process to generate an inverted index based on the corpus posted in the Assignment Files section of Unit 2. In the index part 1 assignment, we created a process that scans a document corpus and creates an inverted index. In the index part 2 assignment, we extended the functionality of the indexing process by incorporating functionality to:
- Ignore (not include the index) a list of stop words.
- Edit tokens as follows:
- Terms under 2 characters in length are not indexed.
- Terms that contain only numbers are not indexed.
- Terms that begin with a punctuation character are not indexed.
- Integrate the Porter Stemmer code into our index.
- Calculate the TF-IDF(t,d) value for each unique combination of document and term.
In this assignment, we will be using the inverted index that was created by the process developed as part of the index part 2 assignment. In unit 4, we learned about the weighting of terms to improve the relevance of documents found when searching the inverted index. First, we learned about calculating the inverse document frequency and from this the TF-IDF(t,d) weight. Using the TF-IDF(t,d) weight, we were able to calculate both document and query vectors and evaluate them using the formula for cosine similarity.
In the development assignment for this unit, we will implement these concepts to create a search engine. Your assignment will be to create a search engine that will allow the user to enter a query of terms that will be processed as a ‘bag of words’ query.
Your search engine must meet the following requirements:
- It must prompt the user to enter a query as a ‘bag of words’ where multiple terms can be entered separated by a space.
- For each query term entered, your process must determine the TF-IDF(t,d) weight as described in Unit 4.
- Using the query terms, your process must search for each document that contains each of the query terms.
- For each document that contains all of the search terms, your process must calculate the cosine similarity between the query and the document.
- The list of cosine similarity scores must be sorted in descending order from the most similar to the least similar.
- Finally, your search process must print out the top 20 documents (or as many as are returned by the search if there are fewer than 20) listing the following statistics for each:
- The document file name.
- The cosine similarity score for the document.
- The total number of items that were retrieved as candidates (you will only print out the top 20 documents).
- ‘Simpson algorithm’ is provided in the output of the search for terms.
This Source Code document contains code for a search engine that meets many of these requirements and is provided for you as an example. This code does NOT meet all of the requirements of this assignment. Further, there are key areas of the code that are missing. You are welcome to use this example code as a baseline. However, you must complete any missing functionality as required by the assignment.
Your submission will be assessed using the following Aspects. These items will be used in the grading rubric for this assignment. Make sure that you have addressed each item in your assignment.
- Was the source code (.py file) for the solution submitted as an attachment to the assignment? (25%)
- Was the output of the search for the term ‘home mortgage’ provided in the posting? (25%)
- Did the output include the following information and were there 20 items or less listed in the output? (50%)
Summary¶
The previous assignment did not mention ignoring terms under 2 characters in length or numbers; so I have included them in this assignment. Here are the results after Ignoring numbers and short words:
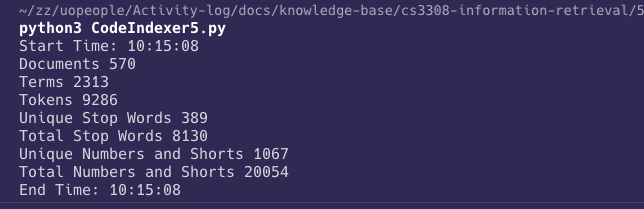
We notice that 1067 terms have been eliminated, that is, 20054 tokens; and this will be considered the base that we will start this assignment from.
In this assignment, we will use the vector space model in my search engine; The basic idea is to build a vector representing each document; and then, when a query is issued, we build a vector representing the query; and then, we calculate the cosine similarity between the query vector and each document vector; and then, we sort the results by similarity, and we print the top 20 results.
To achieve this, we do the following:
- Load the relevant files into indexes (in memory).
- Building the document vectors.
- Starting the interactive search.
- Parsing the query.
- Building the query vector.
- Retrieving the relative documents.
- Filtering the results.
Note: the search function function returns ANY document that contains ANY of the query terms, and this is not what we want; we want to return documents that contain ALL of the query terms; so we will have to modify this function to return the correct results; see section 9 in the changes below.
Let’s review the requirements:
- Was the source code (.py file) for the solution submitted as an attachment to the assignment? (25%)
- I decided that the Indexer file was getting complex; so I split it into five files
CodeIndexer5.py: This file contains the code for the indexer.Search5.py: This file contains the code for the search engine.Utils.py: This file contains the code for the utils functions.stop_words.py: Contains utility functions for stop words.porterstemmer.py: Contains the code for the porter stemmer.
- All of these files are zipped and attached to the assignment.
- I decided that the Indexer file was getting complex; so I split it into five files
- Was the output of the search for the term ‘home mortgage’ provided in the posting? (25%)
- Yes, see the output below, where that last query is
home mortgage, and it returned no results. 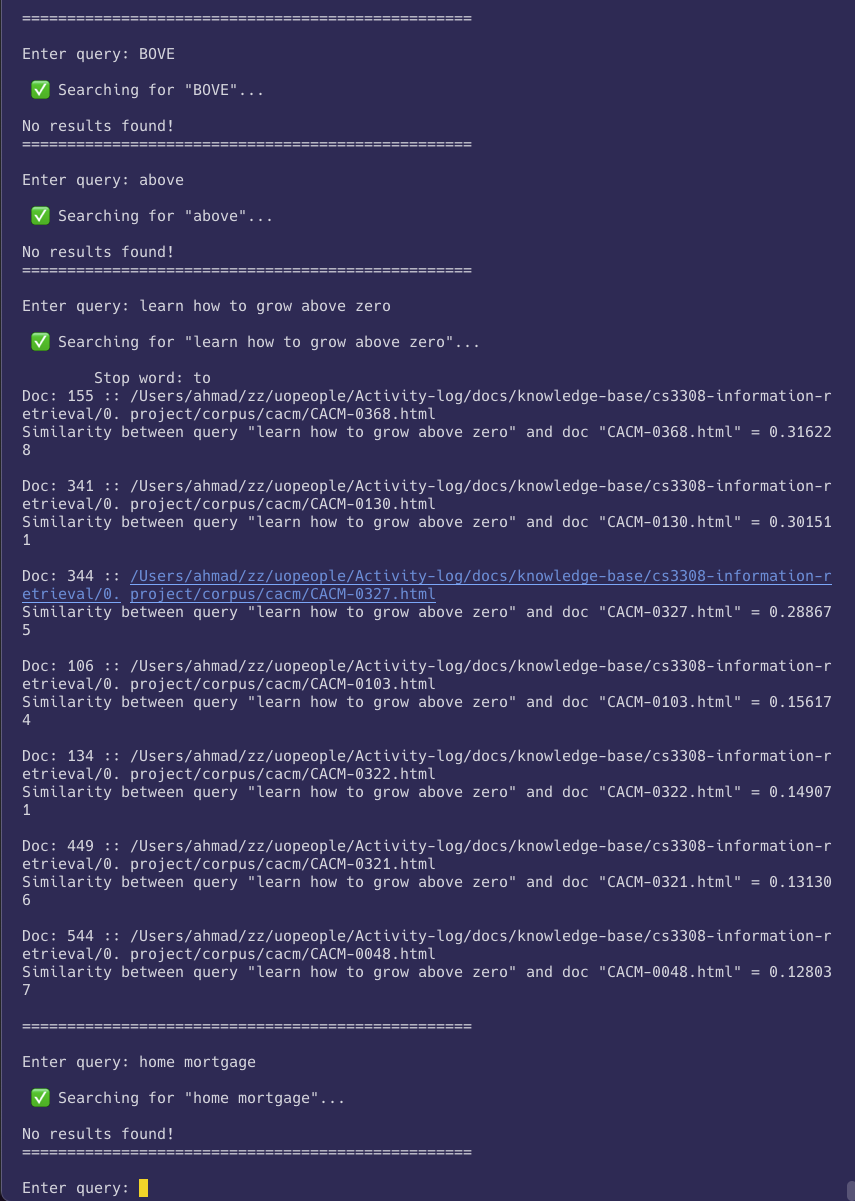
- Yes, see the output below, where that last query is
- Did the output include the following information and were there 20 items or less listed in the output? (50%)
- Yes we limit the results to 20, and we print the following information for each result:
- The document file name.
- The cosine similarity score for the document.
- As I stated below, the corpus that we have is not great; so none of my queries returned more than 20 results.
- Yes we limit the results to 20, and we print the following information for each result:
Changes¶
1. Ignore numbers and short words¶
The previous assignment did not mention ignoring terms under 2 characters in length or numbers; so I have included them in this assignment. I added the following utils functions:
def is_number(s):
try:
float(s)
return True
except ValueError:
try:
int(s)
return True
except ValueError:
return False
def is_short(s, limit=2):
if len(s) <= limit:
return True
else:
return False
I added the following code to the parseToken() function, which ensures that we ignore short words and numbers:
if is_number(lowerElmt) or is_short(lowerElmt):
continue
Here are the results after Ignoring numbers and short words:
2. Load the relevant files into indexes¶
- I used a function called
load_index()inSearch5.py, which loads the relevant files into in-memory indexes. - This function is called at the beginning of the
main()function, and if it fails, it will try to rebuild the index; using the code from the previous assignment inCodeIndexer5.py. - Here is the code:
indexDetails = {
'documents': {
'fileName': 'documents.dat',
'structure': ['docPath', 'docId']
},
'terms': {
'fileName': 'index.dat',
'structure': ['term', 'termId']
},
'postings': {
'fileName': 'postings.dat',
'structure': ['termId', 'docId', 'tf_idf', 'tf', 'idf', 'df']
},
}
terms = {}
inverted_terms = {}
documents = {}
inverted_documents = {}
postings = {}
document_vectors = {}
def load_index():
try:
print("Loading index files...")
global terms, documents, postings
documentsFile = open(indexDetails['documents']['fileName'], 'r')
for line in documentsFile:
line = line.strip()
line = line.split(',')
documents[line[0]] = int(line[1])
documentsFile.close()
termsFile = open(indexDetails['terms']['fileName'], 'r')
for line in termsFile:
line = line.strip()
line = line.split(',')
terms[line[0]] = int(line[1])
termsFile.close()
postingsFile = open(indexDetails['postings']['fileName'], 'r')
for line in postingsFile:
line = line.strip()
line = line.split(',')
postings[(int(line[0]), int(line[1]))] = {
'tf_idf': float(line[2]),
'tf': int(line[3]),
'idf': float(line[4]),
'df': int(line[5]),
}
postingsFile.close()
for term in terms.keys():
termId = terms[term]
inverted_terms[termId] = term
for docPath in documents.keys():
docId = documents[docPath]
inverted_documents[docId] = docPath
except Exception as e:
print(e)
print("Error loading index files, trying to re-build the index...")
return build_index()
3. Building the document vectors¶
- I will use the vector space model in my search engine; so when indexes load, let’s build a vector for each document, and each is an array of M (the number of terms in the index) elements, all of them initialized to 0.
- Then, we loop through all the terms; if the term exists in the document, we set the value of the term in the document vector to the TF-IDF value of the term in the document.
- This will prove useful when calculating the cosine similarity between the query vector and the document vectors.
- This function is named
build_document_vectors(), and it has two dependencies:retrieve_document_postings(documentId): This function retrieves all the postings that a document appears in.build_document_vector(documentId): This function builds a vector for a single document.
- Here is the code:
def retrieve_document_postings(docId):
found_postings = []
for posting in postings.keys():
if posting[1] == docId:
found_postings.append({
'termId': posting[0],
'tf_idf': postings[posting]['tf_idf'],
'tf': postings[posting]['tf'],
'idf': postings[posting]['idf'],
'df': postings[posting]['df'],
})
return found_postings
def build_document_vector(docId):
# init a vector of 0s for each term
vector = [0 for i in range(len(terms.keys()) + 1)]
document_postings = retrieve_document_postings(docId)
for term in terms.keys():
termId = terms[term]
for posting in document_postings:
if posting['termId'] == termId:
vector[termId] = posting['tf_idf']
return vector
def build_document_vectors():
print("Building document vectors...")
for docPath in documents.keys():
docId = documents[docPath]
document_vectors[docId] = build_document_vector(docId)
4. Starting the interactive search¶
- After all of this is loaded; an interactive function starts where the user can enter a query, and the search engine will return the top 20 results.
- This function is named
interactive_search(), and it has two dependencies:build_query_vector(query): This function builds a vector for a single query.retrieve_relative_documents(parsed_query): This function retrieves all the documents that have a score greater than 0.
- It also accepts the following commands:
exit: Exits the program.clear: Clears the screen.rebuild: Rebuilds the index.
- We are going to speak about each dependency in detail in the next sections.
- Here is the code:
def interactive_search():
while True:
query = input("Enter query: ")
if query.lower() == 'exit':
break
if query.lower() == 'clear':
print(chr(27) + "[2J")
continue
if query.lower() == 'rebuild':
print("\n\nRebuilding index...\n")
build_index()
print("\nIndex rebuilt successfully!\n")
load_index()
print("Index loaded successfully!\n")
build_document_vectors()
print("Document vectors built successfully!\n")
continue
print("\n ✅ Searching for \"%s\"...\n" % query)
parsed_query = parse_query(query)
relative_documents = retrieve_relative_documents(parsed_query)
if len(relative_documents) == 0:
print("No results found!")
for doc in sorted(relative_documents, key=lambda x: x['similarity'], reverse=True)[:20]:
docId = doc['docId']
docPath = get_document(docId)
docName = docPath.split('/')[-1]
similarity = doc['similarity']
print("Doc: %i :: %s" % (docId, docPath))
print("Similarity between query \"%s\" and doc \"%s\" = %f" %
(query, docName, similarity))
print("")
print("=" * 50)
print("")
5. Parsing the query¶
- The first thing to do after receiving the query is to parse it, and this is done using the
parse_query(query)function. - This function does the same steps that were used to process tokens in documents; thus, we guarantee the matching between query terms and terms saved in the index.
- This function is named
parse_query(query), and it has one dependency:process_query_term(query_term): This function processes a single query term.
- Here is the code:
def process_query_term(query_term):
lowered = query_term.lower()
if is_stop_word(lowered):
print("\tStop word: %s" % lowered)
return None
elif starts_with_punctuation(lowered):
print("\tPunctuation: %s" % lowered)
return None
elif is_short(lowered):
print("\tShort or number: %s" % lowered)
return None
elif is_number(lowered):
print("\tNumber: %s" % lowered)
return None
else:
stemmed = stemmer.stem(lowered, 0, len(lowered)-1)
return stemmed
def parse_query(query):
query = query.strip()
query = splitchars(query)
parsed_query = []
for term in query:
processed_term = process_query_term(term)
if processed_term in terms.keys():
parsed_query.append({
'term': term,
'processed_term': processed_term,
'termId': terms[processed_term],
})
return parsed_query
6. Building the query vector¶
- Similar to the way that we built the document vectors, we will build a vector for the query.
- This function is named
build_query_vector(query), and it has one dependency:retrieve_query_postings(query_term): This function retrieves all the postings that a query term appears in.
def retrieve_term_postings(termId):
found_postings = []
for posting in postings.keys():
# logger.pprint(posting)
if posting[0] == termId:
found_postings.append({
'docId': posting[1],
'tf_idf': postings[posting]['tf_idf'],
'tf': postings[posting]['tf'],
'idf': postings[posting]['idf'],
'df': postings[posting]['df'],
})
return found_postings
def build_query_vector(parsed_query_words, docId):
vector = [0 for i in range(len(terms.keys()) + 1)]
for term in terms.keys():
if term in parsed_query_words:
termId = terms[term]
term_postings = retrieve_term_postings(termId)
for posting in term_postings:
if posting['docId'] == docId:
vector[termId] = posting['tf_idf']
return vector
7. Retrieving the relative documents¶
- This function relies on the query vector, and it calculates the cosine similarity between the query vector and each document vector.
- If the cosine similarity is greater than 0, then the document is considered a relative document.
- This function is named
retrieve_relative_documents(parsed_query), and it has one dependency:calculate_cosine_similarity(query_vector, document_vector): This function calculates the cosine similarity between two vectors.
def compute_cosine_similarity(queryVector, documentVector):
ql = (len(queryVector))
diqi = 0
for i in range(ql):
diqi += queryVector[i] * queryVector[i]
d2 = 0
for i in range(ql):
d2 += documentVector[i] * documentVector[i]
q2 = 0
for i in range(ql):
q2 += queryVector[i] * queryVector[i]
dominator = sqrt(d2) * sqrt(q2)
if dominator == 0:
return 0
similarity = diqi / dominator
return similarity
def retrieve_relative_documents(parsed_query):
relative_documents = []
for docId in document_vectors.keys():
docVector = document_vectors[docId]
queryVector = build_query_vector([
term['processed_term'] for term in parsed_query
], docId)
sim = compute_cosine_similarity(queryVector, docVector)
if sim > 0:
relative_documents.append({
'docId': docId,
'similarity': sim,
})
return relative_documents
8. Filtering the results¶
- The control then goes back to the
interactive_search()function, where we sort the results by similarity, and we print the top 20 results. - After printing, the control goes back to the user to enter another query.
- See the code for
interactive_search()above.
9. Return documents that contain ALL of the query terms¶
- The corpus that we have is not great; so I decided to keep the function to return any document that contains ANY of the query terms; and I added another function to return documents that contain ALL of the query terms.
- The idea is to ensure that every relevant document has a score greater than 0, and
ALLquery terms appear in the document. - The target function is named
retrieve_relative_documents(parsed_query), and we added a new function namedis_document_contains_all_terms(docId, parsed_query)that checks if a document contains all the query terms. - Here is the modified code:
def is_document_contains_all_terms(docId, parsed_query):
for term in parsed_query:
termId = term['termId']
if (termId, docId) not in postings.keys():
return False
return True
def retrieve_relative_documents(parsed_query):
relative_documents = []
for docId in document_vectors.keys():
docVector = document_vectors[docId]
queryVector = build_query_vector([
term['processed_term'] for term in parsed_query
], docId)
doc_postings = retrieve_document_postings(docId)
sim = compute_cosine_similarity(queryVector, docVector)
if sim > 0 and is_document_contains_all_terms(docId, parsed_query):
relative_documents.append({
'docId': docId,
'similarity': sim,
})
return relative_documents