WA4. Building an IR System - Part 2¶
This text is divided into three parts, starting from my code in the previous assignment:
- Statement: Includes the statement of the assignment, formatted in an easy-to-follow format.
- Summary: description of the assignment, my observations, and final notes. 0.
- Changes: A step-by-step documentation of all my interactions and changes to the code.
Statement¶
Over the past two units (units 2 and 3) you have developed and refined a basic process to build an inverted index. In this unit, you will extend the work that you started by adding new features to your indexer process. Your assignment will be to add new features to your indexer.
Your Indexer must apply editing to the terms (tokens) extracted from the document collection as follows:
- Develop a routine to identify and remove stop words.
- Implement a Porter stemmer to stem the tokens processed by your indexer routine.
- Remove (do not process) any term that begins with a punctuation character.
Your indexer process must calculate frequencies and weighted term measures that can be used to process a query for scoring in the vector space model. As such your index must:
- Determine the term frequency tf(t,d) for each unique term in each document in the collection to be included in the inverted index.
- Determine the document frequency df(t) which is a count of the number of documents from within the collection that each unique inverted index term appears in.
- Calculate the inverse document frequency using the following formula
idf(t) = log(N/df(t))where N is the total number of documents in the collection. - Finally calculate the
tf-idfweighting using the following formula:tf - idf(td) = tf(t,d) × idf(t)
Your indexer must report statistics on its processing and must print these statistics as the final output of the program.
- Number of documents processed
- Total number of terms parsed from all documents
- Total number of unique terms found and added to the index
- Total number of terms found that matched one of the stop words in your program’s stop words list
In testing your indexer process you should create a new database to hold the elements of your inverted index.
Summary¶
The main purpose of the assignment is to prepare a ranked posting list for each term in the collection. The previous assignment was about a single-pass indexer; however, there is not indicator in this assignment that we should implement a single-pass indexer. Thus, my indexer does two passes on the collection: the first pass prepares the terms and frequencies, and the second pass calculates the idf and tf-idf for each term.
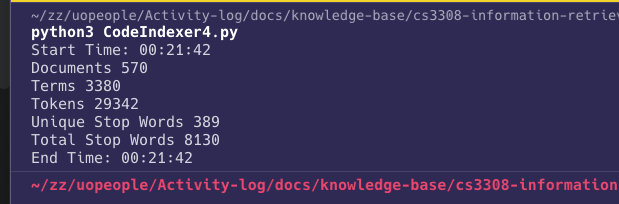
Here are the results of running the indexer against the supplied corpus:
- There are 570 documents in the corpus.
- There are 29342 tokens in the corpus (all words in all documents, excluding stop words, empty strings, and words that start with a punctuation).
- There are 3380 unique terms in the corpus.
- Indexing time is less than 1 second.
- The number of stop words is 8130, of which 389 are unique stop words.
 ¶
¶
Let’s compare it with the result of the previous assignment:
| Statistic | Assignment 2 | Assignment 4 | Difference |
|---|---|---|---|
| Documents | 570 | 570 | 0 (0%) |
| Tokens | 47201 | 29342 | -17859 (-37.8%) |
| Terms | 4280 | 3380 | -900 (-21%) |
- Thus the improvements we did reduced the number of tokens by 37.8% and the number of terms by 21%.
The processing has generated a third file called postings.dat that contains the following structure:
| Term id | DocId | Tf-IDF | Term Frequency | IDF | Document Frequency |
|---|---|---|---|---|---|
The assignment did not specify which database to save to, but since we used files in the previous assignment, I continued with the same approach.
Changes¶
1. Develop a routine to identify and remove stop words¶
- I searched for the stop words in English and I found the list from (Bleier, 2010) and (Stop Words iso, 2023).
- I continued with the list from (Stop Words iso, 2023) because it seemed more complete and standard.
- I added the list to the
stop_wordsvariable in thestop_words.pyfile. - Defined a function called
is_stop_wordin thestop_words.pyfile that takes a word and returnsTrueif it is a stop word. - I added the following code to
parsetokenmethod in the indexer:
# if the token is a stop word then ignore it
if is_stop_word(lowerElmt):
continue
2. Implement a Porter stemmer to stem the tokens processed by your indexer routine¶
- I used the
PorterStemmerclass that is supplied int the assignment instructions. - I imported the stemmer class in the indexer and initialized at the top of the file:
from porter_stemmer import PorterStemmer
stemmer = PorterStemmer()
- I stemmed the lowercased token before processing it:
# stem the token
stem = stemmer.stem(lowerElmt, 0, len(lowerElmt)-1)
- All code in the
parsetokenprocesses now thestemvariable instead oflowerElmt.
3. Remove (do not process) any term that begins with a punctuation character¶
- To remove all terms that starts with a punctuation character, I used the built-in
string.punctuationvariable that contains all punctuation characters. - I defined a function
starts_with_punctuationthat takes a word and returnsTrueif it starts with a punctuation character.
import string
def starts_with_punctuation(term):
return term[0] in string.punctuation if term else False
- Then, I edited the
parsetokenmethod as follows:
# if the token is a stop word or starts with punctuation then skip it
if is_stop_word(lowerElmt) or starts_with_punctuation(lowerElmt):
continue
4. Determine the term frequency tf(t,d) for each unique term in each document in the collection to be included in the inverted index¶
- The following code in the
parsetokenmethod calculates the term frequency for each term in each document:
# if the document is not currently in the postings
# list for the term then add it
if not (documents in database[stem].postings.keys()):
# increment document frequency (within the collection)
database[stem].docFrequency += 1
# init the term frequency (within the document)
database[stem].postings[documents] = 0
# increment term frequency (within the document)
database[stem].postings[documents] += 1
# increment term frequency (within the collection)
database[stem].termfreq += 1
documentsis the id of the current document being processed.- The code above checks if the current document is already in the postings list for the term, if not, it adds it.
- In both cases, it increments the term frequency (within the collection), document frequency (within the collection), adds the
docIdto the postings list, and increments the term frequency (within the document).
5. Determine the document frequency df(t) which is a count of the number of documents from within the collection that each unique inverted index term appears in¶
- The code in the previous step already calculates the document frequency for each term in the collection.
6. Calculate the inverse document frequency using the following formula idf(t) = log(N/df(t)) where N is the total number of documents in the collection¶
- There is a complication here, the
idfis calculated after the whole collection is processed, so that we know the total number of documents in the collection. - Thus it is not possible to complete the indexing in one pass.
- The following code in the
mainfunction does a second pass on the database to calculate theidffor each term on each document:
for k in database.keys():
docIds = database[k].postings.keys()
for docId in docIds:
database[k].idf[docId] = math.log(
documents/database[k].docFrequency)
7. Finally calculate the tf-idf weighting using the following formula: tf - idf(td) = tf(t,d) × idf(t)¶
The code above changed to reflect the new idf calculation:
for k in database.keys():
docIds = database[k].postings.keys()
for docId in docIds:
idf = math.log(documents/database[k].docFrequency)
tf = database[k].postings[docId]
database[k].idf[docId] = idf
database[k].tf_idf[docId] = tf * idf
8. Report total number of terms found that matched one of the stop words in your program’s stop words list¶
- To track this number, 2 more variables were added to the
IndexTermclass:stopWordCountandstarts_with_punctuation_count. - And the following code changed:
stopWordsCount = 0
starts_with_punctuation_count = 0
# ... code ...
# if the token is a stop word or starts with punctuation then skip it
if is_stop_word(lowerElmt):
stopWordsCount += 1
continue
if starts_with_punctuation(lowerElmt):
starts_with_punctuation_count += 1
continue
9. You should create a new database to hold the elements of your inverted index¶
- The last time we used files to hold the database, today I’m doing the same. A new file called
postings.datais created to hold the database. - The data is saved according to the following table:
| Term id | DocId | Tf-IDF | Term Frequency | IDF | Document Frequency |
|---|---|---|---|---|---|
- The following code saves the database to the file:
def write_postings_dot_dat():
global database
postingsFile = open('postings.dat', 'w')
for k in sorted(database.keys()):
termid = database[k].termid
for docId in database[k].postings.keys():
tf_idf = database[k].tf_idf[docId]
tf = database[k].postings[docId]
idf = database[k].idf[docId]
df = database[k].docFrequency
postingsFile.write(str(termid)+','+str(docId)+','+str(tf_idf) +
','+str(tf)+','+str(idf)+','+str(df)+os.linesep)
postingsFile.close()
References¶
- Manning, C.D., Raghaven, P., & Schütze, H. (2009). An Introduction to Information Retrieval (Online ed.). Cambridge, MA: Cambridge University Press. https://nlp.stanford.edu/IR-book/pdf/05comp.pdf. Chapter 6: Scoring, Term Weighting, and the Vector Space Model.
- Bleier S. (2010, August 27). NLTK’s list of English stop words. GitHub Gist. https://gist.github.com/sebleier/554280
- Stop words iso. (2023). stop-words-en. GitHub. https://github.com/stopwords-iso/stopwords-en/blob/master/stopwords-en.txt