7. Introduction to web search¶
Introduction 1¶
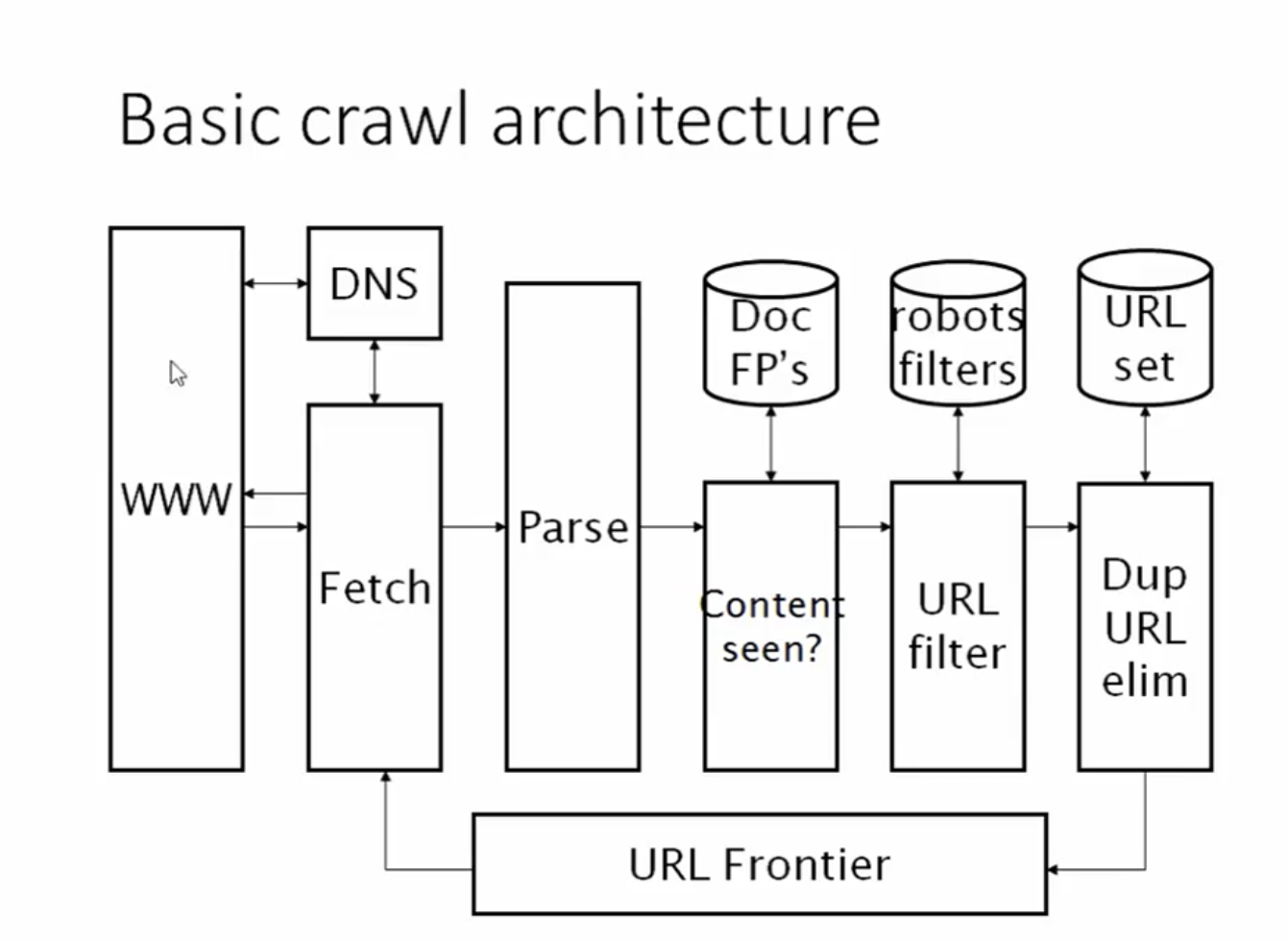
- Web Crawler Operation:
- Begins with a set of seed URLs.
- Fetches the pages at the seed URLs, and extracts the links from them.
- Puts the extracted links into a queue of URLs to be crawled.
- Pop a URL from the queue, and repeat the process on it.
- URL Frontier: The queue of URLs to be crawled, that is, all URLs that have been discovered but not yet crawled.
- Web crawling complications:
- Crawling is not feasible on one machine, it must be distributed.
- Malicious pages can be used to attack crawlers or attack users if they are indexed.
- Spam pages:
- Spam pages are pages that include many keywords but little content; thus returning them in search results is not useful.
- These pages should be detected and removed.
- Spider traps:
- Spider traps are pages that contain many links, but no content; and each page is pointing to another page in the trap.
- These can cause the crawler to get stuck in an infinite loop.
- Such pages should be detected and removed.
- Duplicate pages:
- Duplicate pages are pages that have the same content, but different URLs.
- These should be detected and avoid re-processing them; instead, the crawler should just keep one copy of the page.
- Latency/Bandwidth:
- Crawlers should not overload servers by sending too many requests.
- Webmasters expect to pay for bandwidth that is used by actual users, not crawlers.
- Politeness:
- Crawlers should not hit a server too often.
- Expectations from a Crawler:
- Be polite: Only crawl pages that are allowed to be crawled and respect the robots.txt file.
- Be Robust: Be immune to spider traps, malicious pages, etc.
- Be Distributed.
- Be Scalable.
- Be performant and efficient in managing processing and network resources.
- Fetch higher-quality pages first.
- Continuously crawl the web.
- Be Extensible: Allow for easy addition of new features, new data formats, protocols, etc.
- Robots.txt file: is a file that is placed in the root directory of a website, and it specifies which pages are allowed to be crawled and which are not.
19. 1 Background and History 2¶
- Early search engines were into two categories:
- Full-text index search engines:
- Examples: AltaVista, Excite, Infoseek, etc.
- Provided a keyword search interface, supported by inverted indexes and ranking algorithms similar to those we have seen in the previous chapters.
- They were successful at scaling, however, the relevance of the results started to degrade as the web grew (due to spam pages, idiot content creators, etc.).
- This has led to a new generation of search engines, with spam filtering and new ranking algorithms.
- Taxonomy-based search engines:
- Examples: Yahoo, etc.
- The user navigates through a hierarchy of categories to find the desired page.
- Drawback: classifying pages into the right categories is a difficult task, and it involves human effort that can not scale to the size of the web.
- Advantage: only high-quality pages are included in the index, thus the search results are of high quality.
- Drawback: the number of categories/labels/taxonomies/tags has grown to be too many, and it is difficult to navigate through them.
- Famous Categorizers: About.com, Open Directory Project, etc.
- Full-text index search engines:
19.2 Web characteristics 2¶
- The decentralized, uncontrolled nature of the web is the main challenge for web search engines.
- Creators started to create pages with natural languages, and lots of dialects which require many different forms of stemming and other linguistic processing.
- Because of different types of content and creators, the web is very heterogeneous, that is, no two pages are alike.
- Content creation is not only available to professional writers but also to everyone, thus following the grammar rules is not guaranteed.
- Indeed, web publishing in a sense unleashed the best and worst of desktop publishing on a planetary scale, so that pages quickly became riddled with wild variations in colors, fonts and structure. Some web pages, including the professionally created home pages of some large corporations, consisted entirely of images (which, when clicked, led to richer textual content) – and therefore, no indexable text.
- The democratization of content creation on the web meant a new level of granularity in opinion on virtually any subject. This meant that the web contained truth, lies, contradictions and suppositions on a grand scale.
- The previous points introduced a problem of which pages or writers are trustworthy and which are not, and search engines can not determine that.
- The size of the web:
- In 1995, AltaVista indexed 30 million pages that were all static.
- In 1995, static pages were doubled every few months.
- There is no easy answer to how big is the web because it is constantly changing.
- 19.2.1 The web graph:
- We can view the static Web consisting of static HTML pages together with the hyperlinks between them as a directed graph in which each web page is a node and each hyperlink a directed edge.
- In-links: the set of pages that link to a given page, average: 8 -15 hyperlinks.
- The In-degree of a page is the number of in-links it has.
- Out-links: the set of pages that a given page links to.
- The Out-degree of a page is the number of out-links it has.
- The web graph is not strongly connected, that is, some pages have no in-links or no out-links; there might be some pages with no paths to them from other pages.
- The links in the web graph do not follow a random distribution, but rather a power-law distribution.
- The total number of web pages with an in-degree=i is proportional to 1/i^a (power-law); where a is a constant and it is found to be 2.1.
- The web graph takes a bowtie shape:
- Three major sections
SCC,IN, andOUT. - There are routes from
INtoSCC. - There are routes from
SCCtoOUT. - There are links in between
SCCpages. - There are no routes from
SCCtoIN. - There are no routes from
OUTtoSCC. - There are no routes from
OUTtoIN. INandOUTare of equal size; whileSCCis much larger.- Tubes: are the set of pages that line
INtoOUTdirectly without going throughSCC. - Tendrils:
- Links from
INinto nowhere. - Links from nowhere to
OUT.
- Links from
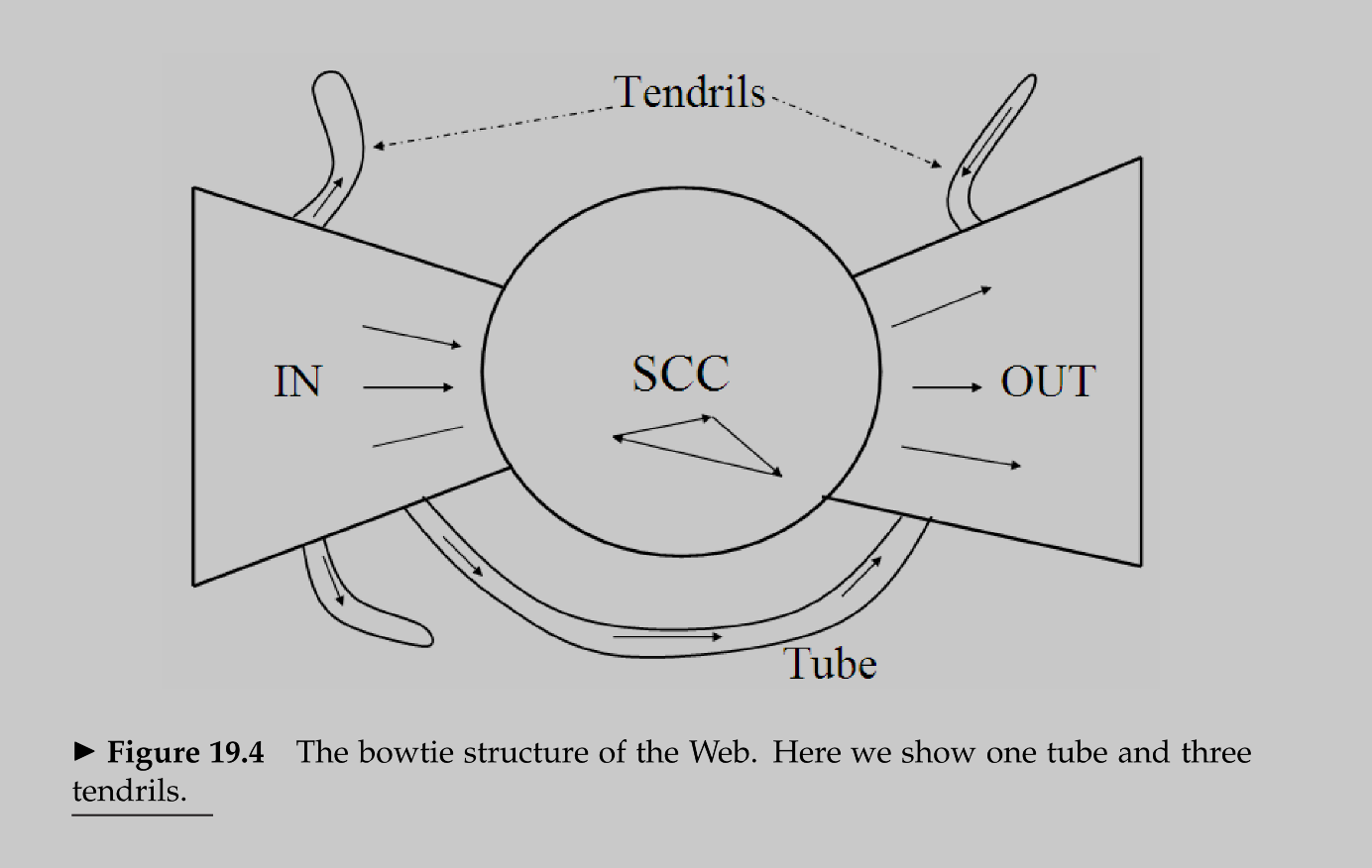
- Three major sections
- 19.2.2 Spam:
- The problem with the old ranking systems is that a page with a higher frequency of a keyword is ranked higher, even if it is not relevant to the query and its information need.
- The early definition of spam was that the page manipulates its content and thus manipulates the ranking algorithm to rank higher.
- Spam techniques:
- List a lot of keywords on the page, with the same color of the background so they don’t appear as text when the page is rendered:
- These keywords are still indexed by the search engine.
- This is useful if the page depends on ads, and any click on the page will generate revenue.
- This has a financial incentive as the page owner will get paid for each click.
- Cloaking:
- The page owner shows different content to the search engine and the user.
- If the HTTP request is coming from a crawler (identified by the user agent), then the page owner will show a page that is tailored to the trick search engine.
- If the HTTP request is coming from a user, then the page owner will show a spam page.
- This is unprecedented in IR systems, as the relationship between page publishers and search engines seems to be not collaborative.
- Doorway page:
- A page that contains data and metadata that is carefully crafted to rank high in search engine results.
- When the doorway page is requested by users, it redirects to a different page containing a content with more commercial nature.
- Manipulate metadata:
- The page owner manipulates the metadata to include a link to another page that is not related to the page content.
- List a lot of keywords on the page, with the same color of the background so they don’t appear as text when the page is rendered:
- Paid inclusion: The page owner pays the search engine to rank the page higher.
- The problem of spam has led an entire industry to emerge: Search Engine Optimization (SEO).
- SEO agencies provide consultancy services for clients to help them rank higher in search results.
- The struggle between SEO agencies (who are constantly trying to manipulate the ranking algorithm) and search engines (who are constantly trying to detect and respond to these techniques) has led to the emergence of Adversarial IR where pages go through link analysis.
19.3 Advertising as the economic model 2¶
- Early in the history of the Web, companies used graphical banner advertisements on web pages at popular websites (news and entertainment sites such as MSN, America Online, Yahoo! and CNN).
- CPM (cost per mil) was the main pricing model, where the advertiser pays a fixed amount for every 1000 impressions (views) of the ad; and the main goal was Branding (brand awareness) to the advertising company.
- CPC (cost per click) was introduced later, where the advertiser pays a fixed amount for every click on the ad (not just views or impressions). The main goal was a transaction-oriented (purchase, registration, etc.).
- The pioneer of CPC was Goto.com (later renamed Overture), which was later acquired by Yahoo.
- For every query q, advertisers bid on the query, and the highest bidder gets the top spot in the search results.
- The search results are ordered by the bid amount.
- Advantage: Users that use GOTO portals for search were committed to the transaction, and thus the conversion rate was high.
- GOTO only paid if the user clicked on the ad, which was a good incentive for advertisers.
- This type of search is called sponsored search or search advertising.
- The pure search engines (Google, AltaVista) and sponsored search engines (GOTO) were combined into a hybrid model which is the current model of search engines.
- The results are divided into two sections: organic and sponsored.
- Each section is ordered by a different ranking algorithm.
- The main response is still organic, but the sponsored section is still important.
- This has led to the emergence of a new industry: Search Engine Marketing (SEM).
- SEM agencies provide consultancy services for clients to help them allocate appropriate budgets for their marketing campaigns based on the SEM’s knowledge of each search engine’s ranking algorithm.
19.4 The search user experience 2¶
- Traditional IR: Users were typically professionals with at least some training in phrasing queries over a well-authored collection whose style and structure they understood well.
- Web Search:
- Users do not know -or care- about the heterogeneity of the web content, query syntax, query phrasing, etc.
- Average keywords in a query: 2 - 3.
- Syntax operators are not used (Boolean connectives, wildcards, etc.).
- Google identified two principles:
- Focus on relevance, that is, precision over recall in the first page of results.
- Lightweight user interface: both search and results pages are simple, less cluttered with graphics, and fast to load.
- 19.4.1 User query needs:
- Web search queries fall into one (or more) of the following categories:
- Navigational: The user is looking for a specific page or website; E.g., “Facebook”, “UoPeople”, etc. Users tend to visit only one page (the homepage, or direct page) from the results.
- Informational: The user is looking for general information about a topic; users tend to visit multiple pages from the results.
- Transactional: The user is looking to perform a transaction (purchase, download a file, make a reservation, etc.).
- Web search queries fall into one (or more) of the following categories:
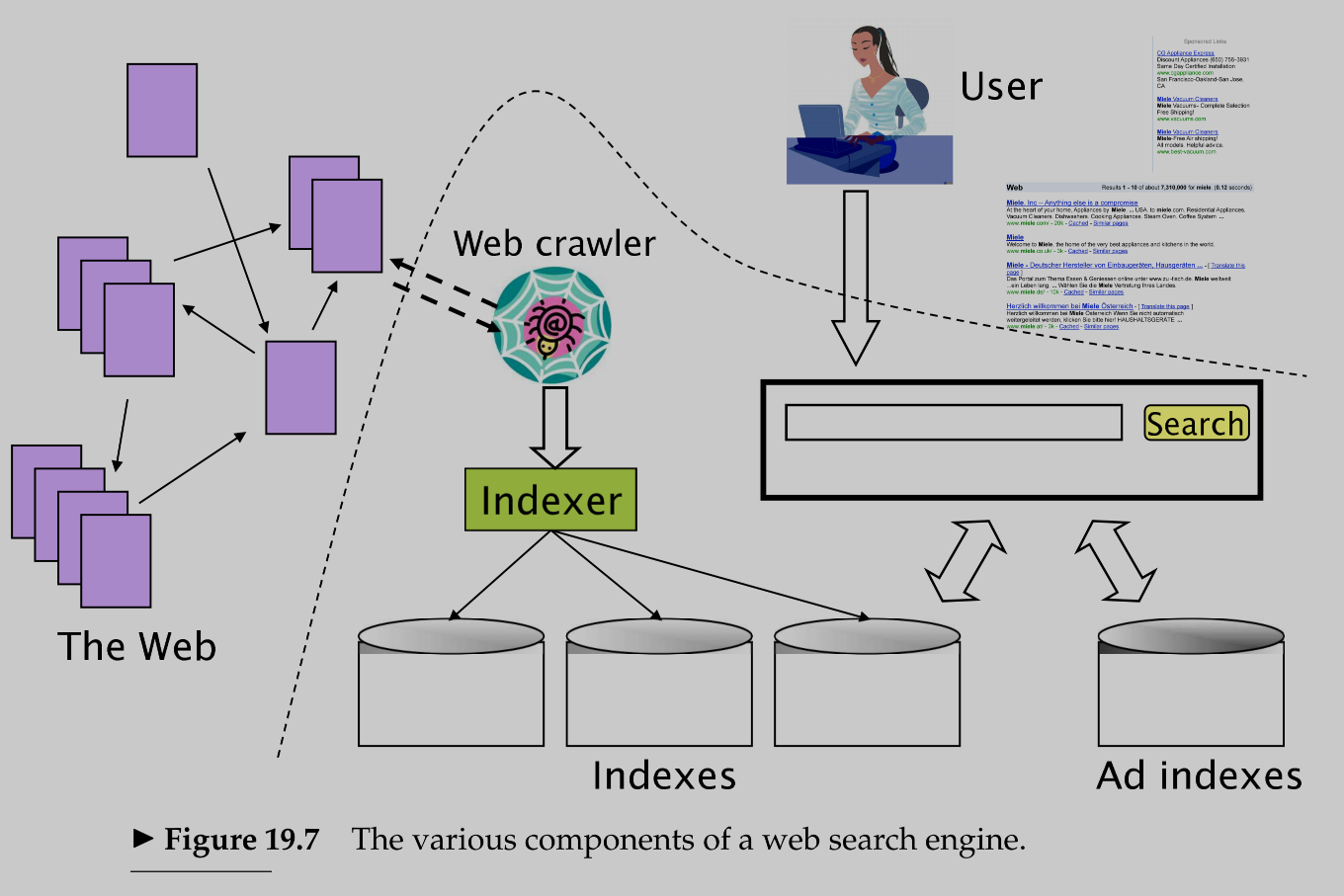
19.5 Index size and estimation 2¶
- Considerations:
- Comprehensiveness grows with the index size.
- Some pages are more informative than others, thus, it does matter which pages are included in the index, and just adding more pages does not necessarily improve the search results.
- There is an infinite number of dynamic web pages, thus, it is hard to determine the fraction of the web that is indexed.
- Some web pages do not return 404 indicating that they do not exist, but rather return a page with a nice message that the page does not exist with a response status of 200, which makes the Crawler’s job harder.
- Search engines only index the first few thousand words of a page and not the entire page.
- Search engines may index a web page because other pages link to it, without actually crawling or indexing the page itself.
- Search engines organize their indexes in different tiers and partitions, and not all of them are examined in response to a query.
- Capture reCapture method:
- Samples of the search engine 1 (SE1) index are chosen.
- Samples of the search engine 2 (SE2) index are chosen.
- All documents from the SE1 sample are searched for in SE2 (and vice versa), where the results are compared to whether the document is indexed on the other search engine or not.
- The results are then compared.
19.6 Near-duplicates and shingling 2¶
- Almost 40% of the web pages are duplicates, either in legitimate or malicious ways.
- Many repositories mirror copies of the same content to increase redundancy and access reliability.
- Search engines should avoid indexing duplicate content, instead, they should index only one copy of the content; and other occurrences should point to the indexed copy.
- Ways to detect duplicates:
- Fingerprinting:
- A page fingerprint is saved and compared to the existing fingerprints.
- The page fingerprint is a succinct (e.g., 64-bit) digest of the characters on that page.
- The fingerprint is computed using a hash function, when it detects a collision, it means that the page is a duplicate.
- Near-duplicates are not detected by this method.
- Shingling:
- It is a technique to detect near-duplicates.
- It is based on the idea that if two documents are similar, then they will share a lot of k-shingles.
- A k-shingle is a sequence of k tokens (words, characters, etc.).
- For each page, we compute the set of k-shingles, and then we compare the sets of k-shingles of two pages.
- The similarity between the two pages is the Jaccard similarity between the two sets of k-shingles.
Jaccard(A, B) = |A ∩ B| / |A ∪ B|- If the Jaccard similarity is above a certain threshold, then the two pages are considered near-duplicates, and the search engine should index only one of them.
- Fingerprinting:
References¶
-
Unit 7 Lecture 1: Introduction to Web Crawling | Home. (2023). Uopeople.edu. https://my.uopeople.edu/mod/kalvidres/view.php?id=392894 ↩
-
Manning, C.D., Raghaven, P., & Schütze, H. (2009). An Introduction to Information Retrieval (Online ed.). Cambridge, MA: Cambridge University Press. Available at http://nlp.stanford.edu/IR-book/information-retrieval-book.html? Chapter 19: Web Search Basics ↩↩↩↩↩↩