8. Web Crawling
20 Web Crawling and Indexes 1¶
20.1 Overview of a web crawler 1¶
- 20.1.1 Features a crawler must provide:
- Robustness: Handle spider traps (infinite loops of pages in a particular domain).
- Politeness: Not hitting a server too frequently, and respecting robots.txt.
- 20.1.2 Features a crawler should provide:
- Scalability: Ability to handle a large number of pages.
- Freshness: Ability to crawl new pages quickly.
- Distributed: Ability to run on multiple machines.
- Extensible: Ability to be extended to support new features.
- Configurable: Ability to be configured to support different policies.
- Adaptable: Ability to adapt to new formats and technologies.
- Efficient: Ability to be efficient in terms of time and space.
- Continuous: Ability to run continuously.
- Spam-resistant: Ability to avoid spamming and overloading servers.
- Trap-resistant: Ability to avoid malicious page or spider traps.
- Quality: Ability to crawl high-quality pages, and avoid low-quality pages.
20.2 Crawling 1¶
- Crawling is the process of traversing the web graph.
- In normal crawling, the URL is removed from the URL frontier after it is crawled.
- In continuous crawling, the URL of a fetched page is added back to the frontier for fetching again in the future.
- The Mercator crawler is the reference crawler for this chapter; it was built in 1999 and it formed the basics for many commercial crawlers.
- To crawl a billion pages a month, the crawler must be able to crawl hundreds of pages per second.
- 20.2.1: The crawler architecture:
- The process of deciding not to crawl a page can be done in two stages:
- Before fetching the page: We consult the robots.txt and other policies, to decide if we should fetch the page. This is helpful if the URL was already added to the URL frontier and the robots.txt changed since then.
- After fetching the page: On the parsed links, we do the filtering on those URLs, and only the URLs that pass the filter are added to the URL frontier.
- Certain housekeeping tasks are typically performed by a dedicated thread:
- Every few seconds, log crawl progress statistics (URLs crawled, frontier size, etc.).
- Decide if the crawler should stop.
- Every few hours, checkpoint the crawl, a snapshot of the crawler’s state (say, the URL frontier) is committed to disk.
- In case of a crash, the crawler can be restarted from the last checkpoint.
- Distributing a crawler:
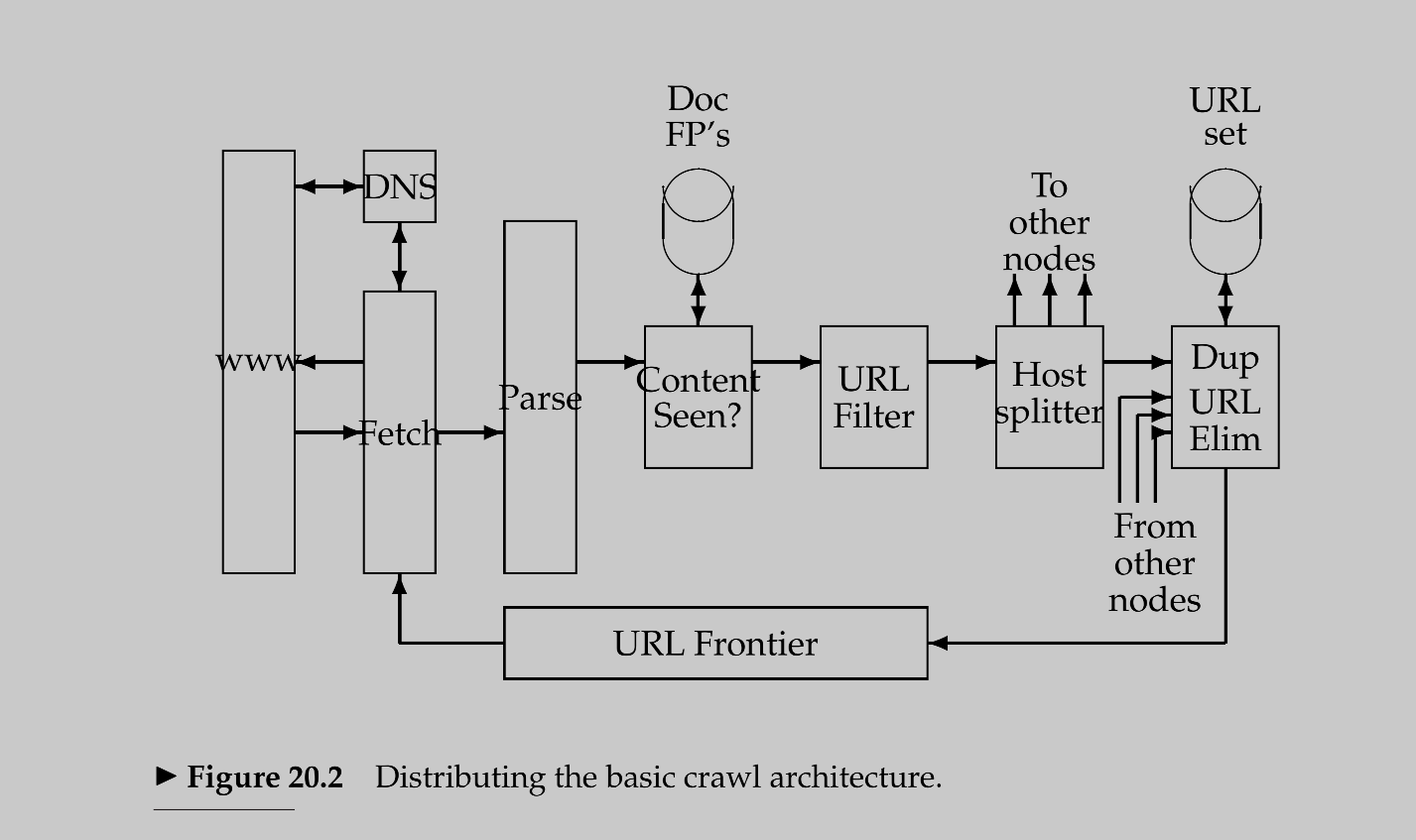
- Different threads run on different processes each at a different machine (node).
- The processes can be geographically distributed, that is, each machine is in a different location and it only crawls pages from that location or nearby locations.
- After the URL filter, a Host Splitter was added with the following missions:
- Send the filtered URLs to the right crawler node that is responsible for crawling this URL.
- The decision is based on the hostname of the URL.
- The set of host names is partitioned across the crawler nodes.
- The Duplication Elimination is done on the node that the URL belongs to as it has the content of other pages to compare and may not be the
current node.
- The process of deciding if the URL has been seen before:
- Requires saving the URL fingerprints in a global database that is accessible by all crawler nodes.
- The fingerprints can NOT be saved locally as content may be duplicated within a different node (different server).
- The decision was that fingerprints be saved in the URL frontier next to the URL itself.
- The process of deciding not to crawl a page can be done in two stages:
- 20.2.2 DNS resolution:
- DNS resolution is the process of converting a domain name to an IP address.
- It is a bottleneck in the crawling process.
- The DNS resolution that is built-in standard libraries is synchronous, that is, other threads are blocked until the current one finishes; thus most web crawlers implement their own DNS resolver as a component of the crawler.
- The DNS resolution has some rules:
- Request times out after a certain time implementing an exponential back-off.
- The waiting time starts at 1 second and ends at 90 seconds.
- It retries 5 times at maximum.
- 20.2.3 The URL frontier:
- The URL frontier at a node is given a URL by its crawl process or by the host splitter of another crawl process.
- High-quality pages are (HQP):
- HQPs are queued differently as they get crawled more frequently.
- The priority of the page and change rate are saved along with the URL in the URL frontier.
- The URL frontier now is a priority queue.
- A crawler should only make one request to a server at a time:
- The problem is other nodes may have URLs from the same server, and may be fetching them at the same time.
- The common solution is to have a time gap between successive requests that is an order of magnitude larger than the last fetch time to that server.
- The Frontier has two major modules (FIFO queues):
- Front Queues F:
- Implements prioritization.
- Contains a separate queue for each priority level.
- When a URL is added to the frontier, a Prioritizer assigns it a priority level, and then it is added to the queue of its priority level.
- Back Queues B:
- It implements politeness.
- Contains a separate queue for each server (hostname).
- It contains an auxiliary table T that connects each server to its queue.
- The URLs flow from the front queues to the back queues according to their hostname and get ordered by their priority level.
- Only when a queue is empty, it requests to be re-filled from the front queues.
- There are 3 times back queues as many as front queues.
- The crawler requests URLs from the back queues.
- Front Queues F:
- The properties of each URL Frontier Item:
- ID.
- URL.
- Priority.
- Change rate.
- Last fetch time.
- Fingerprints.
- etc.
20.3 Distributing indexes 1¶
- Two Distributing implementations:
- Partitioning by terms, also known as global index organization:
- Each subset of terms is stored on a different node along with postings for those terms.
- A query is routed to the right node(s) according to the terms in the query.
- Each query may hit multiple nodes in parallel.
- Merging the results from multiple nodes turns out to be expensive.
- Load balancing is difficult, as a spike in particular query terms may overload a certain node(s). E.g. all people searching for the same news.
- Clustering is difficult, as the terms may be distributed across multiple nodes.
- Implementing dynamic indexing is difficult.
- Partitioning by documents, also known as local index organization:
- Each node stores the entire index for a subset of documents.
- Each query is sent to all nodes.
- The results merging is easier, as each node returns the final results to that query.
- Maintaining the term stats and ranking (e.g. IDF) is harder, as it requires gathering information from all nodes; but a solution was made to have background processes that gather info, compute states, and then periodically update the nodes.
- Partitioning by terms, also known as global index organization:
- With the crawling process, maintaining all documents of a host on a separate node seems to be a good idea.
20.4 Connectivity servers 1¶
- Web search engines require a connectivity server that supports connectivity queries on the web graph.
- Connectivity Queries:
- E.g. What URLs point to a given URL? What URLs does a given URL point to?
- Queries that ask about the in-links or out-links of a given URL.
21 Link Analysis 2¶
- Link analysis for web search has intellectual antecedents in the field of citation analysis, aspects of which overlap with an area known as bibliometrics (the study of statistical analysis of books, articles, or other publications).
- Link spam: creating a large number of pages that link to a target page in order to increase the target page’s PageRank.
- Link analysis use cases:
- Citation analysis (bibliometrics).
- Web crawling (decide what page to crawl next and its priority).
21.1 The Web as a graph 2¶
- The anchor text of a link is a good description of the target page.
- The anchor tag represents an endorsement of the target page by the source page (or its author).
- 21.1.1 Anchor text and the web graph
- The crawler may store all anchor text for a particular URL across all pages that link to it.
- The stored terms in all anchor text can be used to index the target page.
- The term postings for terms appearing in anchor texts can include these URLs (marked separately from the terms within the page).
- We’ll call these terms that appear in anchor text anchor text terms.
- The anchor text terms are also weighted by their frequency in anchor text.
- The very common anchor text terms are ignored. E.g. “click here” or “more”.
- The anchor text terms can be exploited in ranking algorithms:
- E.g. Publishing a large number of links to an organization’s URL with a bad name.
- E.g. For Publishing a large number of links with text
evil orgtohttps:://microsft.com; then that page will be ranked high for the queryevil orgthus, destroying the reputation of Microsoft.
- The window around the anchor text terms can be used to:
- Extract a snippet for the target page.
- Detect spam.
21.2 PageRank 2¶
- Every node in the web graph is a page and is assigned a score called PageRank.
- Random walk: When a user is on a page, they may follow a link to another page, and then another, and so on.
- Teleport: The user jumps from one page to another page, that has no link in the current page; thus, the user is teleported from one node to a very far node in the graph (e.g. manually entering a URL in the browser).
- 21.2.1 Markov chains:
- Markov chain:
- It is a discrete-time stochastic process, a process that occurs in a series of time steps in each of which a random choice is made.
- It consists of N states and a transition probability matrix P (N x N).
- The entries of each row in the matrix are a probability distribution over the N states, each between 0 and 1, and the sum of each row is 1.
- The probability of each entry depends only on the current state, and not on the way that led to that state.
- We can view a random surfer on the web graph as a Markov chain:
- One state for each web page.
- Each transition probability represents the probability of moving from one web page to another.
- Markov chain:
21.3 Hubs and Authorities 2¶
- For a given query and every web page, we compute two scores:
- Hub score:
- How well the page represents the query.
- These pages contain many links to good authority pages, but they may not be good authorities themselves.
- Hub pages are used to discover authority pages.
- The hub score of a page is the sum of the authority scores of the pages it links to.
- Authority score:
- How well the page is a good source of information for the query.
- Suitable for board-topic searches, such as informational queries.
- Hub score:
- 21.3.1 Choosing the subset of the Web:
- Given a query (say leukemia), use a text index to get all pages containing leukemia. Call this the root set of pages.
- Build the base set of pages, to include the root set as well as any page that either links to a page in the root set or is linked to by a page in the root set.
- The base set is used to compute the hub and authority scores.
References¶
-
Manning, C.D., Raghaven, P., & Schütze, H. (2009). An Introduction to Information Retrieval (Online ed.). Cambridge, MA: Cambridge University Press. Chapter 20: Web crawling and Indexes. http://nlp.stanford.edu/IR-book/pdf/20crawl.pdf ↩↩↩↩↩
-
Manning, C.D., Raghaven, P., & Schütze, H. (2009). An Introduction to Information Retrieval (Online ed.). Cambridge, MA: Cambridge University Press. Chapter 21: Link Analysis http://nlp.stanford.edu/IR-book/pdf/21link.pdf ↩↩↩↩